Git
Git este o modalitate de version control, creată pentru a gestiona proiecte întregi, pentru a urmări evoluția sa în timp, pentru a facilita munca în echipă și pentru a avea oricând un backup al proiectului.
Version control
Version control se referă la urmărirea și gestionarea modificărilor făcute asupra proiectelor. Acestea îi ajută pe programatori să lucreze mai rapid și mai inteligent. Deoarece sunt stocate într-o bază de date din cloud, orice modificare sau greșeala făcută poate fi inversată. Un exemplu concret poate fi apariția unui bug la nivelul celei mai noi surse a proiectului. Mulțumită version controlului, aceasta poate fi comparată linie cu linie cu orice altă versiune mai veche pentru gasirea mai rapidă a problemei.
Git repositories
Un git repository este un folder .git aflat în fișierul rădăcină al proiectului. Aici sunt stocate infomațiile cu privire la proiect, precum istoricul modificărilor. Acesta are o versiune separată, stocată în cloud, într-o bază de date a unui third party precum GitLab sau GitHub. Cele două se pot sincroniza cu ajutorul comenzilor de git, despre care vom vorbi puțin mai târziu. Un git repository poate fi inițializat direct într-un proiect sau poate fi clonat pentru a fi folosit de alți programatori.
Setup
În acest curs vom folosi un IDE numit CLion. De asemenea vom folosi compilatorul de la Visual Studio.
- Instalați Visual Studio Community Edition și CLion.
Odată instalat VS, acesta trebuie configurat din Visual Studio Installer.
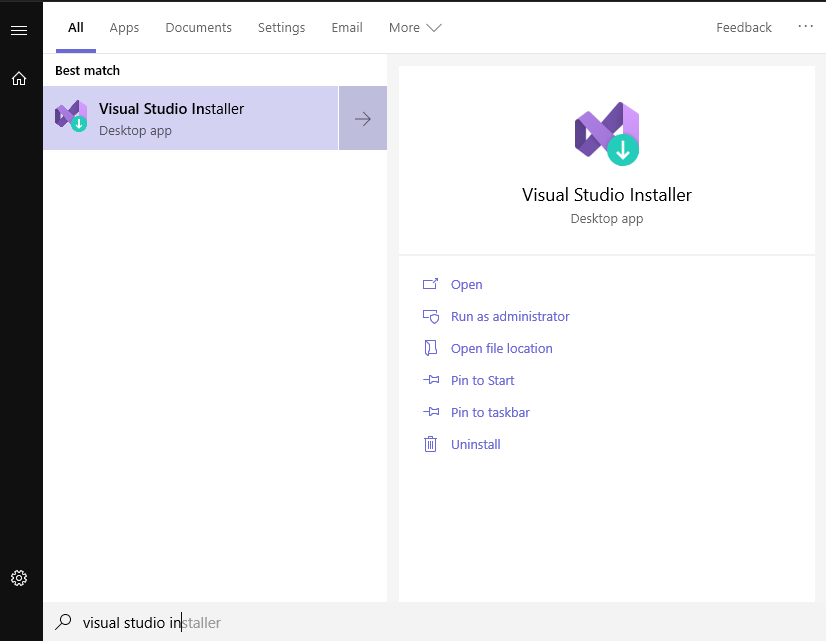

Accesând opțiunea de Modify, putem selecta pachetele pe care le dorim. Avem nevoie numai de Desktop Development with C++, restul pot fi debifate.
- Instalați Git.
Odată instalat Git, acesta trebuie configurat cu un username si un email, care vor apărea în commiturile efectuate ulterior.
git config --global user.name "John Doe"
git config --global user.email [email protected]
Pentru a vedea setările curente, puteți apela
git config --list
De asemenea, ne trebuie o cheie ssh, pentru a putea clona mai departe proiectele. Pentru a o genera trebuie apletă comanda ssh-keygen, pentru care vom lăsa valorile cerute ca default, apăsând enter când consola va cere un input. După aceea vom apela cat ~/.ssh/id_rsa.pub pentru a o afișa.
ssh-keygen
cat ~/.ssh/id_rsa.pub
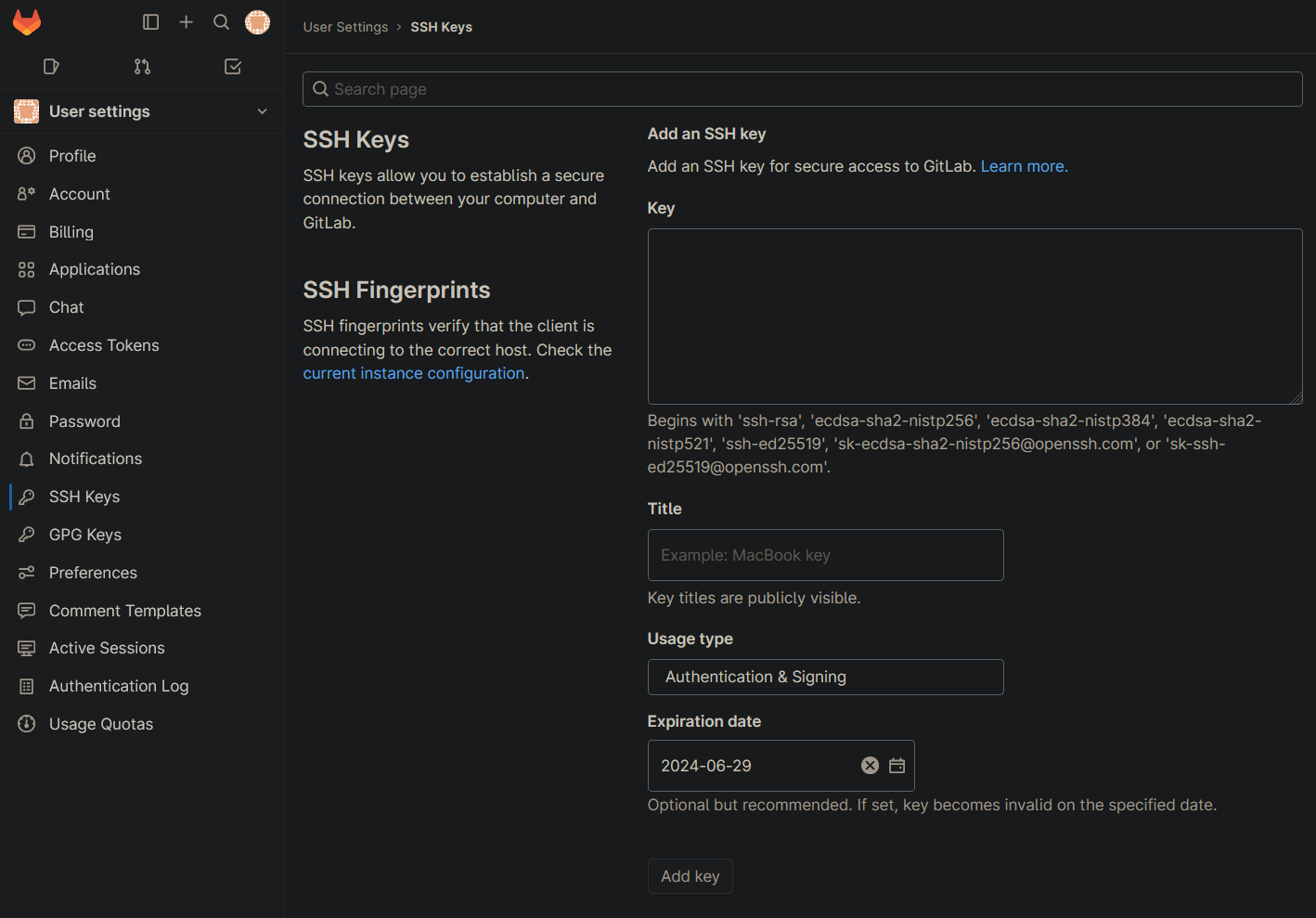
Copiați cheia, deoarece aceasta trebuie inserată în GitLab. Pentru a o adăuga, accesați Profile/ Edit profile/ SSH Keys, de unde puteți adăuga o cheie nouă.
Inițializare
Inițializarea se face local, apelând comanda git init în root folder. Aceasta va crea un nou folder .git, unde vor fi salvate toate informațiile cu privire la repository. Cu toate acestea, o metodă mai simplă este clonarea.
Clonare
O metodă foarte simplă și cunoscută de creare locală a unui proiect de git este clonarea. Aceasta se bazează pe existența unui proiect remote, pe care îl copiază local. Pașii care trebuie urmați utilizând platforma GitLab (aceștia sunt similari și pentru alte platforme, precum GitHub):
-
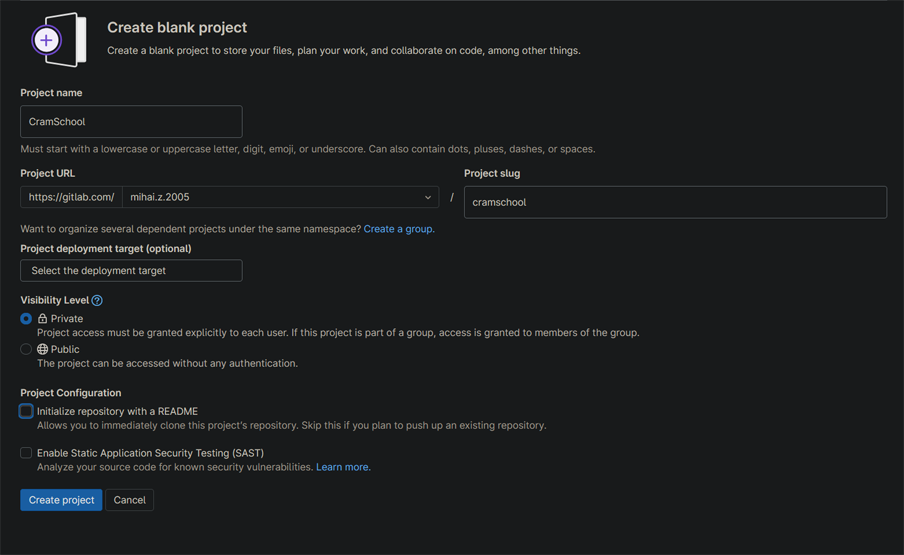
Crearea unui nou repo pe GitLab, unde se vor completa numele proiectului, adresa URL a acestuia (unde se poate specifica userul pentru care este făcut proiectul sau grupul) și vizibilitatea
-
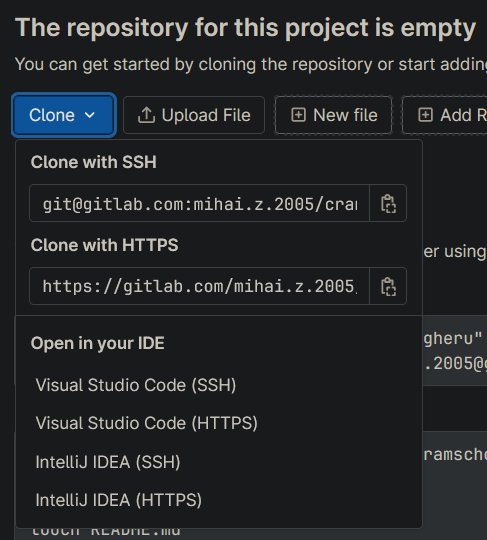
Obținerea adresei SSH (recomandat) sau URL a proiectului
-
Clonarea sa locală
git clone [email protected]:username/projectname.git
Acum că proiectul se află local, îi putem face modificări.
Întreținerea unui repo
În folderul nou apărut putem crea ce fișiere dorim, pe care apoi să le sincronizăm cu repo-ul din cloud, apelând căteva funcții din consolă. Pentru a adăugă schimbările se folosește comanda git add, urmată de sursă. Dacă dorim să verifiDacă vrem să dăm push la întreg proiectul vom folosi git add ..
Dacă dorim să verificăm schimbările detectate, putem apela comanda git status. Fișierele scrise cu verde sunt modificate și adăugate la commit, iar cele cu roșu nu fac parte din acesta.
Apoi, trebuie sa creăm un commit, folosind comanda git commit -sm, urmat de numele comitului. Acesta ar trebui să fie cât mau sugestiv cu putință.
Pasul final este sa apelăm comanda git push, care va da submit la commit, iar acesta va fi actualizat în cloud.
În acest mod, repo-ul local este sincronizat cu cel remote.
cd projectname
git add .
git status
git commit -sm "Commit Name"
git push
Fișiere speciale
Git recunoaște mai multe tipuri de fișiere ca fiind speciale. Printre acestea se numără .gitignore, care specifică fișierele sau folderele care sunt ignorate de git și nu sunt incluse în commit. Acesta are scopul de a nu ocupa spațiul limitat de pe GitLab cu fișiere mari, precum imagini sau librării, care nu au legătură cu funcționalitatea proiectului sau există deja în mediul online și sunt ușor de obținut. Un exemplu de astfel de fișier, special pentru CLion se află aici.
Un alt fișier special este README.md, care are ca scop scrierea unei documentații cu privire la proiect, din care să reiasă scopul proiectului, modul de utilizare și poate chiar cel de funcționare. Acesta este scris în markdown. Proiectul poate fi creat de la început cu un README din pagina de creare de pe GitLab.

De asemenea, mai există fișiere precum .gitattributes, .gitmodules sau .mailmap, ale căror funcționalități se pot găsi aici.
Branches
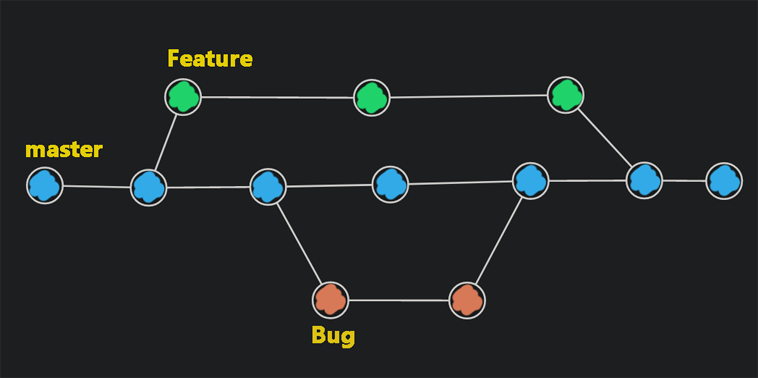
Un branch este o alta versiune a proiectului inclusă în repo. Un repo poate găzdui mai multe branchuri. Acestea te ajută să lucrezi la un feature specific al proiectului sau la a avea mai multe versiuni ale proiectului. De exemplu, un proiect poate avea un master branch, care sa fie versiunea oficială a sa, și un develop branch, în care programatorii să lucreze. Atunci cand o nouă versiune este gata, cele doua branchuri pot fi merge-uite, astfel actualizând varianta oficială a proiectului.
Orice proiect de git are default un branch master. Pentru a crea un branch nou se poate apela git checkout -b branchname. Pentru a schimba branchul activ, se poate apela git checkout branchname.
Merge Request
Atunci când vrem să unim branchurile, de exemplu cand am creat un branch separat pentru a rezolva un bug, iar acum vrem să propagăm schimbările în master branch, putem să facem merge între branchuri. Dacă ne situam în brancul master master(prin apelarea git checkout master), putem apela git merge branchname pentru a adăuga schimbările facute în branchul branchname la master branch.
Exerciții
Acum vom crea un repo pentru un proiect:
- Creați un repo nou pe GitLab și inițializați-l cu un fișier
README.md. - Faceți o clonă locală a repo-ului.
- Creați un folder
srcînrootși adăugați fișierele create în Cursul 4. - Da-ți commit la
root.
Stiluri de Programare
Un stil de programare este un set de reguli utilizate la scrierea codului. Acesta are scopul de a facilita înțelegerea programului și de a minimiza riscul apariției de buguri. Regulile pot varia de la limbaj la limbaj sau de la echipă la echipă. Este important ca acestea să fie respectate de toți participanții la proiect, pentru a-și putea înțelege munca unul altuia. Cu timpul veți observa că în proiectele mari acesta este strict necesar să aveți un stil de programare, deoarece acestea devin prea complexe pentru a fi înțelese ușor și pentru a le fi reținută funcționalitatea.
Convenții de denumire
Pentru denumirea variabilelor, funcțiilor, claselor, fișierelor, etc. este important să urmați o convenție de denumire concisă, din care să reiasă scopul precis al blocului denumit. Acestea ar fi câteva reguli generale de denumire:
- Toate denumirile ar trebui să fie descpriptive, dar concise.
void ComputePlayerHeight() {
...
}
- Abrevierile ar trebui evitate, dar nu eliminate. Variabilele cu nume lungi nu sunt o problemă, însă uneri ar putea fi ocolite.
uint32_t playerID;
-
Numele ar trebui să fi scrise legat. În cpp nu sunt comune underscore-urile drept în mijlocul numelor.
-
Constantele sunt de obicei scrise cu majuscule, cuvintele fiind în acest caz despărțite de underscore-uri.
const Transform DEFAULT_POSITION;
- Numele nu ar trebui să includă informație duplicată, atunci când este posibil.
enum PlayerStateEnum {
// Name should be PlayerState
};
Indentare și Spații
Indentarea codului are scopul de a-l face mai citeț. Cu toate acestea, în alte limbaje precum python, aceasta este strict necesară. Pentru limbajul cpp există mai multe reguli de indentare și spațiere.
- Liniile libere servesc scopul de a separa grupuri logice din cod.
Colour GenerateRandomColour {
uint32_t colourR = Random.Range(0, 255);
uint32_t colourG = Random.Range(0, 255);
uint32_t colourB = Random.Range(0, 255);
float colourA = 1;
Colour newColour = Colour(colourR, colourG, colourB, colourA);
return newColour;
}
- Funcțiile ar trebui separate de 1-2 linii acolo unde au implementarea.
void Animal::UpdateHealthByIncrement(uint32_t increment) {
...
}
void Animal::UpdateHungerByIncrement(uint32_t increment) {
...
}
- Taburile ar trebui să aibă un număr constant de spații libere. Un număr comun este 3.
- Spațiile ajută la citirea mai ușoară a codului. Aici sunt câteva exemple de scriere absolut necesare:
Like this a = (a + b) * c;
Not like this a=(a+b)*c;
Like this while (true) {}
Not like this while (true){}
Like this for (int i = 0; i <= n; i++) {}
Not like this for (int i=0;i<=n;i++) {}
Like this if(Condition()) {
DoSomething();
...
}
else {
DoNothing();
...
}
Not like this if(Condition()) DoSomething();
else DoNothing();
Alte Reguli
- Lungimea liniilor de cod ar trebui să nu depășească o măsură fixă. De obicei aceasta este de 80 de caractere.
Vector2D screenSize = Screen::GetScreenSize() * currentScreenSizeModifier -
Vector2D(screenPaddingX * 2, screenPaddingY * 2);
Uneori, pentru a evita astfel de situații, e bine să mai creăm variabile. Acest lucru ajută și la lizibilitatea codului.
Vector2D maxScreenSize = Screen::GetScreenSize();
Vector2D screenPadding = Vector2D(screenPaddingX * 2, screenPaddingY * 2);
Vector2D frameSize = maxScreenSize * currentScreenSizeModifier - screenPadding;
- Consistency is key!
Un exemplu de reguli
Acestea au fost doar câteva reguli generale, care ar trebui respectate mereu când scriem în cpp. Cu toate acestea am pregătit un set de reguli pe care îl folosesc eu.
Variabile
- Numele variabilelor încep cu literă mică.
void HandleMovement(double deltaTime);
- Dacă variabilele aparțin unei clase, sunt precedate de un identificator, de exemplu
m_pentru membrii șis_pentru membrii statici.
Vector3D m_size;
static Mesh s_mesh;
- Membrii claselor sunt privați, declarați la finalul definiției clasei.
class Player {
...
private:
State m_state;
bool m_isHidden;
...
};
- Membrii claselor au un getter și un setter, fiind funcții inline din header.
class Player {
...
public:
inline State GetState() { return m_state; }
inline void SetState(State state) { m_state = state; }
...
};
Funcții
- Numele funcțiilor încep cu literă mare.
void Update();
- Numele funcțiilor sunt scrise fără underscore-uri, fiecare cuvânt începând cu literă mare, folosind abrevieri unde este necesar.
void GenerateGameObjectID();
-
Poziționarea acoladelor se respectă în tot proiectul: fie pe același rând cu declararea, fie pe rândul imediat următor.
-
Blocurile de implementare a funcțiilor sunt separate de câte un spațiu acolo unde aparțin aceluiași segment logic, putând adăuga mai multe spații pentru cele vare diferă în logică.
GameObject::GameObject() {
...
}
GameObject::~GameObject() {
...
}
void GameObject::InitMesh() {
...
}
Clase, structuri, enum-uri
- Numele încep cu literă mare.
class GameObject {
};
-
Numele sunt scrise fără underscore-uri, fiecare cuvânt începând cu literă mare. Abrevierile ar trebui evitate.
-
Declararea unei instanțe este complet separată de definire.
// Așa da
struct GameObject {
};
GameObject cube;
// În niciun caz așa
struct GameObject {
} cube;
Fișiere
-
Numele încep cu literă mare.
-
Numele pot fi scrise folosind underscore-uri, fiecare cuvânt începând cu literă mare.
Game_Object.h -
Fiecare strcutură de date va avea câte un fișier corespunzător sau mai multe.
TimeManager.hșiTimeManager.cpp
Variabile, referințe și pointeri
Comportamentul obișnuit al operatorului de atribuire (=) în C++ este să copieze valoarea unei variabile în alta. Asta înseamnă că există 2 blocuri de memorie complet separate alocate și fiecare variabilă poate fi modificată independent de cealaltă.
Referințe
Acest comportament nu este singurul posibil. Cel mai probabil că sunteți deja familiari cu noțiunea de "referințe":
void f(int x, int &y) {
x++;
y++;
cout << x << ' ' << y << '\n';
}
...
int main() {
int a = 0;
int b = 5;
f(a, b);
}
În acest exemplu, e impropriu să spunem că y își poate modifica valoarea în afara funcției. Atât x cât și y își modifică valoarea în interiorul funcției, dar există 4 variabile în total.
Snippetul de cod de mai devreme este echivalent cu:
int main() {
int a = 0;
int b = 5;
// Începe "f"
int x = a;
int &y = b;
cout << x << ' ' << y << '\n';
}
** TODO desen 2 referințe pe aceeași adresă **
Poate că acel int &y = x arată mai puțin cunoscut decât exemplul din semnătura funcției, dar se aplică același concept. y este o referință la variabila b. Există un singur bloc de memorie de 4 bytes alocat, și ambele variabile lucrează pe ea la comun. Așadar, dacă ar fi să executăm y = 10 după ultimul snippet, și b ar avea valoarea 10.
O scurtă introducere în concepte de memorie
Pentru a putea vorbi despre pointeri, trebuie pusă in context puțin noțiunea de memorie. Vom revizita subiectul în mult mai mult detaliu în cursurile următoare, dar pentru moment, ce trebuie să știți e că fiecare variabilă ocupă o spațiu în RAM.
RAM, disk, și cum lucrăm cu fiecare
Atunci când spunem memorie, mereu ne referim la RAM. Laptopurile moderne au, de obicei, pe undeva între 8GB si 16GB de RAM, cu unele mai performante aflându-se pe la 32GB. Aici se declară și variabile indiferent dacă sunt scalari, tablouri, declarate local, global sau alocate dinamic. Reamintim și conversiile între unitățile de măsura a spațiului de stocare:
- 8b (bit) = 1B (Byte)
- 1000B (Byte) = 1KB (Kilobyte)
- 1000KB (Kilobyte) = 1MB (Megabyte)
- 1000MB (Megabyte) = 1GB (Gigabyte)
- 1000GB (Gigabyte) = 1TB (Terabyte)
Spațiul pe disk este unde instalați aplicații și țineți directoare (folder) si fișiere (file). Pentru a interacționa cu diskul, trebuie deschise fișiere care pot fi citite, scrise, mutate, sau orice altceva ne permite sistemul de operare să facem cu ele.
Tipuri de date și dimensiunile lor
Tipurile de date cu care suntem obișnuiți: int, long long, float și așa mai departe nu trebuie să aibă neapărat o dimensiune fixă în memorie. Nu scrie nicăieri în standardele de C sau C++ că aceste tipuri de date trebuie să fie de o anumită dimensiune, ceea ce înseamnă că o arhitectură nouă de procesor sau chiar și un compilator mai exotic pe arhitecturile cunoscute ar putea să nu respecte dimensiunile cu care suntem noi obișnuiți (mai mult despre asta în cursurile următoare). Acestea fiind zise, în mediul în care scrieți cod la liceu e aproape sigur că veți avea de a face cu următoarele dimensiuni:
bool,char= 1Bshort,unsigned short= 2Bint,unsigned,float= 4Blong long,unsigned long long,double= 8B
Atunci când declarăm o variabilă, sistemul de operare ne alocă (en: allocate) spațiul necesar. Din cum sunt gândite sistemele de operare uzuale (MacOS, Windows, Linux și cel mai probabil orice ați mai atins vreodată), ele permit indexarea memoriei la dimensiune de minim 1B. Acesta e motivul pentru care tipul de date bool consumă 8 biți întregi, chiar dacă ar avea în teorie nevoie de unul singur. Pur și simplu nu putem cere mai puțină memorie. Un lucru important de menționat este că atunci când declarăm orice fel de tablouri, memoria alocată este contiguă (en: contiguous) - elementele sunt la rând, unul după celălalt. De exemplu, dacă declarăm int v[100], va fi un singur bloc de 400B.
TODO desen bloc contiguu de memorie
Pointeri
Un pointer este practic o variabilă de tip întreg (dimensiunea diferă) ce reține o adresă de memorie. Putem declara un pointer astfel int *ptr = &x, unde x este o variabilă de tip int.
TODO desen pointer la un int
Anatomia declarării unei variabile
Declararea de mai sus introduce câteva elemente noi. În primul rând, * și & sunt simboluri cu câte 2 semnificații. Hai să le detaliem:
- Declararea unei referințe:
&înint &x = ysimbolizează căxeste o referință la variabilayde tipint - Referențiere:
&în&xeste adresa de memorie a primului byte utilizat în reprezentarea valorii din variabilax - Declararea unui pointer:
*înint *ptr = &xsimbolizează căptrreține adresa de memorie de la care începe reprezentarea valorii din variabilaxde tipint - Dereferențiere:
*în*ptrobține valoarea de la adresa reținută în pointerulptr
intul din față nu este tipul pointerului, ci tipul de date al valorii de la adresa indicată de pointer. În esență, dereferențierea unui pointer la int va forma un int din cei 4B începând cu adresa reținută. Asta înseamnă că după o secvență de instrucțiuni de forma:
unsigned int x = 1094795585; // 01000001 01000001 01000001 01000001
char *ptr = (char *) &x; // pointer la primul byte din x
char ch = *ptr; // valoarea primului byte din x
cout << ch << '\n';
se va afișa caracterul cu codul ASCII 65, 'A'.
Un detaliu important de menționat este că există și pointeri de tip void *. Nu înseamnă ca rețin adresa unei variabile de tip void, asta nu ar avea sens, ci se comportă ca un placeholder pentru atunci când tipul de date nu e cunoscut. Un pointer de tip void * nu poate fi dereferențiat.
Orice pointer poate avea ca valoare o adresă speciala, nullptr. Este un placeholder care înseamnă ca pointerul nu arată către nimic. De obicei, pointerii ar trebui inițializați pe nullptr, și funcțiile care întorc pointeri de multe ori întorc nullptr dacă eșuează. Un pointer care conține această valoare nu poate fi dereferențiat.
Exerciții
-
Menționați ce afișează următoarea secvență sau dacă are erori de compilare sau de runtime:
int x = 6; int *ptr1 = &x; int *ptr2 = ptr1; *ptr2 = 4; cout << x << ' ' << *ptr2 << '\n';R: 4 4
-
Menționați ce afișează următoarea secvență sau dacă are erori de compilare sau de runtime:
int *ptr = (int *) 2; cout << ptr << '\n';R: 0x2
-
Menționați ce afișează următoarea secvență sau dacă are erori de compilare sau de runtime:
int *ptr = (int *) 2; cout << *ptr << '\n';R: Undefined behaviour
-
Menționați ce afișează următoarea secvență sau dacă are erori de compilare sau de runtime:
int x = 2; int y = 4; int *ptr1 = &x; int *&ptr2 = ptr1; ptr2 = &y; cout << *ptr1 << '\n';R: 4
Alocare dinamică
Cu toții știm să alocăm memorie static (de ex: int v[100]), unii poate ați mai lucrat și cu STL (de ex: vector<int> v), dar v-ați întrebat vreodată ce face STL în spate? În acest capitol vom începe să răspundem la întrebare.
Memorie
Atunci când declarăm variabile, avem câteva opțiuni pentru unde să fie mai exact memoria alocată.
TODO desen memorie si toate tipurile de memorie Memorie pe heap, stivă, globală, constantă
C style
Pentru a aloca memorie dinamic în C, există câteva funcții pe care ne bazăm.
malloc
void *malloc(std::size_t size) ia ca argument un întreg size și întoarce un pointer la începutul unui bloc contiguu de memorie de size bytes. Întoarce nullptr dacă eșuează.
malloc e cel mai de bază mod de a aloca memorie pe heap în limbajul C. Dacă vrem să alocăm un vector de 100 de numere întregi și să îl folosim ca pe un array, putem aborda astfel:
uint32_t *v = (uint32_t *) malloc(100 * sizeof(uint32_t));
if (v == nullptr) {
std::cerr << "Failed to allocate";
}
Acest array poate fi folosit mai departe cum sunteți deja obișnuiți cu un array alocat static:
for (int i = 0; i < 100; ++i) {
v[i] = i;
}
calloc
void *calloc(size_t num, std::size_t size) ia ca argument întregii num și size și întoarce un pointer la începutul unui bloc contiguu de memorie de size * num bytes inițializat pe 0.
Un exemplu similar cu cel de la malloc de mai sus:
uint32_t *v = (uint32_t *) calloc(100, sizeof(uint32_t));
va rezulta într-un array de 100 de întregi, toți setați pe 0.
free
Atunci când alocăm memorie dinamic, este responsabilitatea noastră să o și eliberăm. Dacă omitem să facem asta, riscăm să consumăm din ce în ce mai multă memorie cât timp rulează programul fără a o folosi la ceva, ocupând inutil RAMul utilizatorului și uneori chiar cauzând probleme mai grave. De exemplu, când crasheaza un joc, adesea este din cauza unor memory leakuri (memorie alocată care nu mai poate fi accesată) pentru că a ajuns să consume mai multă memorie decât îi poate oferi sistemul de operare.
void free(void *ptr) ia ca argument pointer către începutul unui bloc de memorie pe care îl va elibera.
realloc
void *realloc(void *ptr, std::size_t new_size) ia ca argument un pointer către începutul unui bloc de memorie pe care îl va muta și dimensiunea pe care trebuie să o aibă noul bloc. Întoarce adresa de memorie de la începutul noului bloc de memorie sau nullptr dacă eșuează. În cazul în care eșuează, blocul original de memorie este păstrat, altfel este eliberat.
Având acces la realloc, putem aloca puțină memorie pentru o structură de date inițial, după care o putem realoca într-o zonă mai mare atunci când este nevoie. De exemplu, vectorii din STL își dublează dimensiunea de fiecare dată când se apelează un push_back care nu ar mai putea fi efectuat în memoria deja existentă.
memset
void* memset(void* dest, int ch, std::size_t count) ia ca argument o adresă de memorie, o valoare ch și un număr de bytes și setează count bytes începând cu adresa dest pe ultimul byte al valorii ch.
De exemplu, pentru a seta un array static v de numere naturale pe 1061109567, putem apela:
memset(v, 0x3f, sizeof(v));
Atenție! Pentru uint32_t v[100], sizeof(v) întoarce 100 * sizeof(uint32_t) = 400. Pentru uint32_t *v = (uint32_t *) malloc(100 * sizeof(uint32_t)), sizeof(v) întoarce dimensiunea unui pointer pe platforma pe care este rulat codul (cel mai probabil 4 sau 8).
Exerciții
-
Se citesc până la
EOFnumere între1și1000000din fișierulcramschool.in. Afișați la consolă numărul de numere și numerele fără să citiți de mai multe ori din fișier. Exemplu Input5 8 7 1 231 5343 11 112 998 4Output
10 5 8 7 1 231 5343 11 112 998 4 -
Se dă
nnumăr natural care se poate reprezenta pe 32 de biți fără semn. Fără a declara tablouri statice sau cu STL, creați o matrice bidimensionalămatdenlinii șincoloane astfel încât următoarea secvență de cod să compileze și să ruleze cu outputul dat: Exemplu Codfor (int i = 0; i < n; ++i) { for (int j = 0; j < n; ++j) { mat[i][j] = i + 1; } } for (int i = 0; i < n; ++i) { for (int j = 0; j < n; ++j) { std::cout << mat[i][j] << ' '; } std::cout << '\n'; }Input
5Output
1 1 1 1 1 2 2 2 2 2 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5
Class & Struct
Declararea unei clase implică definirea unui nou tip de date. Ea conține structura pe care o va urma un obiect (en: object) -- o variabilă declarată ca acest tip nou de date. Obiectul are identitate (poate fi diferențiat de alte obiecte similare), stare (valorile variabilelor care vin "la pachet cu ea") și comportament (funcții care vin "la pachet" cu ea).
În C++, class și struct sunt același lucru. Există o unică diferență, minoră, detaliată mai jos. O clasă numită Vector2 ce reține coordonatele unui vector bidimensional, împreună cu o variabilă vec de tip Vector2 ar putea fi definite astfel:
class Vector2 {
float x, y;
};
...
int main() {
Vector2 vec;
return 0;
}
Identitatea unui obiect este dată de adresa de memorie la care se află, aceasta fiind, în mod evident, unică. Starea obiectului se referă la valorile variabilelor declarate în clasă - în această situație, starea ar fi determinată de vec.x și vec.y. Pentru a adăuga comportament la obiectul nostru, vec, putem defini metoda (en: method, def: funcție definită ca parte dintr-o clasă) sum:
class Vector2 {
float x, y;
Vector2 vectorSum(Vector2 &other) {
Vector2 result;
result.x = x + other.x;
result.y = y + other.y;
return result;
}
};
Access Specifier
Cu clasa definită mai sus, putem declara variabile, dar nu putem accesa nimic din conținutul lor. Secvența:
int main() {
Vector2 vec;
vec2.x = 1.f;
}
nu compilează, pentru că, implicit, fieldurile și metodele din clase sunt private. Din acest motiv, nu avem acces la fieldul x din Vector2, decât atunci când scriem cod în interiorul clasei. Aceasta este și singura diferență între class și struct în C++.
Access specifierele din C++ sunt următoarele:
public: accesibil atât în clasă, cât și în exteriorul claseiprivate: accesibil doar în clasăprotected: accesibil doar în clasă și în clase care moștenesc (en: inherit) de la clasă (mai multe despre asta la Inheritance)
Așadar, pentru a putea accesa x și y din variabila vec, am putea declara astfel:
class Vector2 {
public:
float x, y;
Vector2 vectorSum(Vector2 &other) {
Vector2 result;
result.x = x + other.x;
result.y = y + other.y;
return result;
}
};
Directiva public: (ca și celelalte două) are efect până când este specificat altul, deci ambele variabile și metoda sunt toate accesibile din afara clasei. Secvența următoare ar funcționa acum:
int main() {
Vector2 u;
u.x = 1.f;
u.y = 2.f;
Vector2 v;
v.x = 0.f;
v.y = 3.f;
Vector2 sum = u.sum(v);
return 0;
}
pentru a apela o metodă de pe un obiect, sintaxa este similară cu cea pentru a accesa o variabilă membru.
this
this este un pointer către obiectul curent. Metoda sum definită mai sus ar putea fi scrisă astfel:
class Vector2 {
public:
float x, y;
Vector2 vectorSum(Vector2 &other) {
Vector2 result;
result.x = this->x + other.x;
result.y = this->y + other.y;
return result;
}
};
și ar avea aceeași semnificație. this este implicit.
Observație: Operatorul -> este o combinație între * și .. this->x este o formă mai comodă de a scrie (*this).x și funcționează pentru orice pointer.
Constructor
Constructorul este un bloc de cod care se execută atunci când un obiect este creat. Clasa noastră Vector2 cu un constructor ar putea arăta așa:
class Vector2 {
public:
float x, y;
Vector2() {
x = 0.f;
y = 0.f;
}
...
};
Declararea unei variabile de tip Vector2 utilizând acest constructor poate fi oricare dintre variantele:
Vector2 vecVector2 vec()Vector2 vec = Vector2()
Atunci când declarăm noi un constructor, cel implicit dispare. Asta înseamnă că în situația:
class Vector2 {
public:
float x, y;
Vector2(float x, float y) {
this->x = x;
this->y = y;
}
...
};
putem declara variabile de tip Vector2 doar în următoarele moduri:
Vector2 vec(1.f, 3.f)Vector2 vec = Vector2(1.f, 3.f)
Vector2 vec de exemplu, ar da eroare de compilare, pentru că nu mai există niciun constructor cu 0 argumenți. Nu ne oprește nimeni, în schimb, să ne declarăm noi unul:
class Vector2 {
public:
float x, y;
Vector2() {
x = 0.f;
y = 0.f;
}
Vector2(float x, float y) {
this->x = x;
this->y = y;
}
...
};
Destructor
Destructorul se apelează în momentul în care un obiect este distrus (explicit sau dacă iese din scope). Aveți deja o înțelegere intuitivă a noțiunii de scope. În principiu, se reduce la "acoladele" între care se află o variabilă. Atunci când programul trece de acea acoladă închisă, variabila declarată se pierde și este apelat destructorul.
class Vector {
private:
// Putem inițializa membri și așa, se execută înaintea constructorului
uint32_t *v = nullptr;
Vector(uint32_t length) {
v = (uint32_t *) malloc(length * sizeof(uint32_t));
}
~Vector() {
free(v);
}
};
int main() {
{
Vector v; // Se apelează constructorul și memoria este alocată
} // Se apelează destructorul și memoria este eliberată
return 0;
}
Exerciții
Rezolvați fiecare dintre următoarele cerințe și testați codul pe câteva exemple simple:
- Definiți o clasă
Point2Dcare reprezintă coordonatele unui punct în plan. - Definiți o clasă
Squarecare conține următoarele metode și orice variabile membre utile:float area(): calculează și întoarce aria pătratuluifloat perimeter(): calculează și întoarce perimetrul pătratului
- Adăugați la clasa
Squareun constructor fără parametri și un destructor care scriu la consolă câte un mesaj diferit. - Adăugați la clasa
Squareun constructor care ia ca parametru colțul din stânga sus și perimetrul pătratului și inițializează corect variabilele membre.
Alocare Dinamică, C++ style
malloc și free își fac treaba foarte bine, dar odată cu apariția claselor a apărut nevoia pentru un mod de a aloca dinamic memorie prin care se apelează constructorul.
new
new T alocă memorie pentru un obiect de tipul T, apelează constructorul și întoarce un pointer către acesta. Se pot specifica și parametri pentru constructor.
Pentru a aloca un tip de date de bază:
uint32_t *ptr = new uint32_t;
Pentru a aloca un obiect cu alt constructor decât cel implicit:
Vector2 *vec = new Vector2(1.f, 3.f);
unde Vector2 are definiția:
class Vector2 {
public:
float x, y;
Vector2() {
x = 0.f;
y = 0.f;
}
Vector2(float x, float y) {
this->x = x;
this->y = y;
}
};
delete
delete ptr apelează destructorul și eliberează memoria alocată pentru obiectul aflat la adresa ținută în ptr.
new[]
new T[len] alocă memorie contiguă pentru len obiecte de tipul T și apelează constructorul implicit pentru fiecare în parte, dacă T este clasă.
Pentru a aloca un array de len elemente cu tip de date de bază:
uint32_t *u = new uint32_t[len]; // Neinițializate
uint32_t *v = new uint32_t[len](); // Inițializate cu 0
Pentru a aloca un array de len obiecte de tip T:
T *v = new T[len]; // Constructorul cu 0 parametri
delete[]
delete[] v apelează destructorul pe fiecare element din arrayul care începe la adresa v și eliberează memoria alocată.
Atenție: delete v în loc de delete[] v șterge doar primul element dacă este apelat pe un array. Pointerul la array este în același timp pointerul la primul element.
Exerciții
- Creați o clasă
ListNodecare conține un număr naturalinfoși 2 pointeri către alteListNodeuri inițialize penullptr. - Adăugați un constructor care ia ca argument un singur
uint32_t info. - Adăugați o metodă
ListNode *insertAfter(const uint32_t &info)care inserează un nou nod după cel curent, păstrează integritatea listei dublu înlănțuite și întoarce adresa noului nod. - Adăugați o metodă
void printList()care afișează lista dublu înlănțuită începând cu nodul curent. - Adăugați o metodă
ListNode *erase()care elimină din lista dublu înlănțuită nodul curent, păstrează integritatea listei și întoarce adresa următorului nod din listă. - Adăugați o metodă și variabile membru utile astfel încât fiecare nod din
ListNodesă rețină și divizorii primi ai număruluiinfo, fără a consuma inutil memorie și fără a crea memory leakuri. - Creați o clasă
TreeNodecare conține un număr naturalinfoși un array alocat dinamic de pointeri către fiii nodului. - Adăugați un constructor care ia ca argument un singur
uint32_t info. - Adăugați un constructor care ia ca argument un
uint32_t infoși unTreeNode *fathercare creează un nod nou și îl adaugă ca fiu al noduluifather, dacă acesta este diferit denullptr. - Adăugați o metodă
TreeNode *addChild(TreeNode *child)care adaugă un nod deja existent ca fiu al nodului curent. - Adăugați o metodă
TreeNode *createChild(const uint32_t &info)care creează un nod nou cu informațiainfoși o adaugă ca fiu al nodului curent. - Testați și asigurați-vă că nu aveți memory leakuri.
Inheritance, Encapsulation, Polymorphism
Am vorbit despre clase, dar nu am stabilit cu adevărat ce scop au ele încă. O latură foarte importantă este reprezentată de noțiunea de încapsulare, care implică să ascundem funcționalitate și stare de cod din exteriorul clasei și de moștenire, care ne permite să ajută foarte mult să refolosim cod.
Encapsulation
Încapsularea se referă la situația în care nu expunem aproape deloc starea obiectului către cod din exteriorul clasei astfel încât să fie imposibil de ajuns cu stări invalide. Primul pas în direcția asta este să implementăm mereu funcții de tip "getter" și "setter".
În exemplul de mai jos este modelată foarte simplificat logica odometrului unui autoturism. Nu ar fi de dorit să se poată modifica numărul de kilometri parcurși fără a fi incrementat 1 câte 1, pe parcurs ce mașina este condusă. Soluția este să nu expunem efectiv variabila kmCounter, ci doar o metodă simplă care o afectează cum ne dorim noi.
class Odometer {
private:
uint32_t kmCounter = 0;
public:
void incrementKM() {
kmCounter++;
}
};
Am menționat mai sus noțiunea de funcții de tip "getter" și "setter", dar încă nu am subliniat exact la ce se referă:
class Employee {
private:
std::string name;
uint32_t id;
public:
std::string getName() {
return name;
}
void setName(const std::string &name) {
this->name = name;
}
};
Poate că par inutile aceste funcții pe exemple așa de mici, dar lucrurile se schimbă pe parcurs ce evoluează codul și apar diverse efecte care trebuie să aibă loc în momentul în care se schimbă câte o variabilă. Filozofia în industrie se bazează pe faptul că tot codul ar trebui scris preventiv, în caz că se întâmpla ceva neașteptat, pentru că efortul este mult mai mare să repari ceva din urmă decât să îl scrii cât mai general din prima (aici intervine și alocarea dinamică).
Inheritance
Moștenirea între clase implică preluarea comportamentului unei clase mai generale pentru implementarea unor alte clase, mai specifice. De exemplu:
class Animal {
protected:
std::string name;
uint32_t age;
// Constructorul trebuie sa fie public, altfel nu putem crea obiecte
public:
Animal(const std::string &name, const uint32_t &age) {
this->name = name;
this->age = age;
}
std::string getName() {
return name;
}
void setName() {
this->name = name;
}
uint32_t getAge() {
return age;
}
};
class Dog: public Animal {
public:
Dog(const std::string &name, const uint32_t &age): Animal(name, age) {}
};
class Cat: public Animal {
public:
Cat(const std::string &name, const uint32_t &age): Animal(name, age) {}
};
int main() {
Cat cat("Joe", 3);
cat.setName("Tom");
std::cout << cat.getName() << '\n'; // Tom
}
Această secvență de cod funcționează deoarece clasa Cat a moștenit de la clasa Animal toate variabilele și metodele. Dacă am încerca să modificăm direct numele pisicii din main, nu ar funcționa datorită directivei protected: din clasa părinte. De asemenea, toată această funcționalitate există și pe Dog.
Au apărut câteva elemente noi de sintaxă în acest exemplu, anume class Cat: public Animal și Cat(const std::string &name, const uint32_t &age): Animal(name, age). public din definiția clasei, nu se referă la membrii clasei Cat, ci la ce se întâmplă cu membrii clasei Animal odată ce sunt moștenite. De cele mai multe ori vom specifica public, dar avem următoarele opțiuni:
public: toți membrii și metodele clasei părinte își păstrează access specifierul în clasa fiuprotected: ceea ce este public în clasa părinte devine protected în clasa fiu, iar în rest totul rămâne la felprivate: toți membrii și metodele clasei părinte devin private în clasa fiu
Mai exact:
class Cat: protected Animal {
...
}
nu ne-ar fi permis să apelăm cat.getName() în main(), dar ar fi putut fi apelat dintr-o eventuală clasă fiu a lui Cat.
Celălalt element interesant de sintaxă, Cat(const std::string &name, const uint32_t &age): Animal(name, age) specifică faptul că trebuie apelat constructorul cu 2 parametri din Animal în loc de cel implicit care nu mai există. Constructorul clasei părinte primește argumenții clasei fiu ca atare, urmând să inițializeze cele 2 variabile.
Atenție: Constructorii se apelează pe rând, începând cu clasa părinte și incheind cu clasa instanțiată. Destructorii se apelează tot la rând, dar în ordine inversă. Nu este posibil să fie instanțiată o clasă sau distrus un obiect fără să se apeleze toți constructorii și destructorii din toate clasele strămoș.
Polymorphism
Polimorfismul se referă la proprietatea obiectelor de tip clasă fiu să se comporte ca și cum ar fi clasa părinte, până este nevoie de detalii de implementare specifice. Construind pe exemplul de mai sus, am putea crea un array de pointeri de tip Animal * în care să instanțiem Cat și Dog:
vector<Animal *> animals;
animals.push_back(new Dog("Azorel", 4));
animals.push_back(new Cat("Tom", 2));
Adăugăm la clasa Animal metoda requestFood():
class Animal {
protected:
std::string name;
uint32_t age;
public:
Animal(const std::string &name, const uint32_t &age) {
this->name = name;
this->age = age;
}
void requestFood() {
std::cout << name << " is hungry!";
}
...
};
class Dog: public Animal {
public:
Dog(const std::string &name, const uint32_t &age): Animal(name, age) {}
};
class Cat: public Animal {
public:
Cat(const std::string &name, const uint32_t &age): Animal(name, age) {}
};
În această situație, dacă executăm pentru exemplul anterior cu vectorul de Animal *:
animals[0]->requestFood();
animals[1]->requestFood();
ambele vor afișa mesajul din Animal::requestFood().
Observatie: Operatorul :: se numește "scope resolution operator" și înseamnă că ne referim la simbolul din dreapta care face parte din simbolul din stânga.
Method Overload
Avem posibilitatea de a implementa comportament mai specific pe fiecare clasă fiu în parte:
class Animal {
protected:
std::string name;
uint32_t age;
public:
Animal(const std::string &name, const uint32_t &age) {
this->name = name;
this->age = age;
}
void requestFood() {
std::cout << name << " is hungry!\n";
}
...
};
class Dog: public Animal {
public:
Dog(const std::string &name, const uint32_t &age): Animal(name, age) {}
void requestFood() {
std::cout << name << ": Woof!\n";
}
};
class Cat: public Animal {
public:
Cat(const std::string &name, const uint32_t &age): Animal(name, age) {}
void requestFood() {
std::cout << name << ": Meow!\n";
}
};
Cu această implementare, am putea să executăm ceva de genul:
vector<Animal *> animals;
animals.push_back(new Dog("Azorel", 4));
animals.push_back(new Cat("Tom", 2));
animals.push_back(new Animal("Tweety", 8));
animals[0]->requestFood(); // "Azorel is hungry!"
animals[1]->requestFood(); // "Tom is hungry!"
animals[2]->requestFood(); // "Tweety is hungry!"
Constatăm o problemă: toate cele 3 apeluri au executat codul din Animal::requestFood, și nu din propria clasă. Motivul este că pointerul este de tip Animal * la toate cele 3 obiecte, așa că programul nu se va uita decât în implementarea din clasa Animal. Acest comportament se numește overload și este dorit.
Method Override, Virtual Method
Adesea, overload nu este ceea ce ne dorim. Pentru aceste situații, există comportamentul de override care poate fi obținut cu următoarea sintaxă:
În Animal:
virtual void requestFood() {
std::cout << name << " is hungry!\n";
}
În Cat și Dog:
void requestFood() override {
...
}
În acest caz, apelurile metodei se vor comporta astfel:
vector<Animal *> animals;
animals.push_back(new Dog("Azorel", 4));
animals.push_back(new Cat("Tom", 2));
animals.push_back(new Animal("Tweety", 8));
animals[0]->requestFood(); // "Azorel: Woof!"
animals[1]->requestFood(); // "Tom: Meow!"
animals[2]->requestFood(); // "Tweety is hungry!"
Keywordul override nu este strict necesar, dar dacă îl punem, codul nu va compila decât dacă metoda din clasa părinte este virtual. Ca atare, este indicat să specificăm override de fiecare dată. virtual specifică faptul că vrem să se execute metoda de pe tipul de date al obiectului, nu tipul de date către care crede pointerul că arată.
Abstract Class
În exemplul nostru cu animale, nu are foarte mult sens să putem crea un obiect de tip Animal, având în vedere că nu știm ce tip de animal este, ce sunete scoate etc. Soluția pentru asta este simplă. Dacă definim metoda Animal::requestFood ca:
virtual void requestFood() = 0;
și lasăm Cat::requestFood și Dog::requestFood nemodificate, metoda rămâne neimplementată și nu vom mai putea instanția obiecte de tip Animal, doar de tip Cat sau Dog. O metodă fără implementare se numește pur virtuală (en: pure virtual) și o clasă care nu poate fi instanțiată se numește abstractă (en: abstract class). Scopul claselor abstracte este exact cel din exemplu: să implementeze o parte din comportament (logica de nume si vârstă) fără a permite obiecte incomplete să existe. Astfel, secvența noastră de cod se va comporta la fel ca mai devreme, doar că new Animal("Tweety", 8) ar da eroare de compilare și ar trebui șters înainte.
Observație: Noțiunea de interfață apare des în literatură, dar în C++ înseamnă doar o clasă pur abstractă, anume o clasă care are toate metodele pur virtuale. Interfețele sunt folosite ca să definească modul în care va fi utilizat un obiect, dar fără să se știe încă detaliile de implementare.
Exerciții
La fiecare dintre următoarele cerințe puteți adăuga membri, metode, sau orice vi se pare util. Aveți voie cu STL, nu aveți voie să alocați un număr aleator de obiecte și să vă bazați că ajung.
-
Creați clasa
Vector2care conține:x: număr realy: număr real
-
Creați clasa
Arrow(considerăm că săgețile se mișcă drept și uniform și că sunt punctiforme) care conține:position: punct în plantargetPoint: punct în planspeed: număr real exprimat în unități/tură
-
Creați clasa
Bowcare poate să tragă cu săgeți:position: punct în planArrow *shootArrow(const Point2D &target, const float &speed): trage cu o săgeată în direcția și cu viteza datăvoid move(const Point2D &newPosition): mută arcul la poziția dată
-
Creați clasa
Targetce reprezintă o țintă care poate fi nimerită de săgeți:position: punct în planradius: raza cercului acoperit de țintă, în unități
-
Creați un sistem turn-based în care execuția rulează la infinit și reacționează la următoarele directive:
shoot x y lifetimeundexșiysunt coordonatele unui punct în plan. O săgeată apare la poziția arcului se mișcă un anumit număr de unități, și dispare dupălifetimeturestopoprește programulshowafișează coordonatele tuturor țintelor, săgeților și a arcului și numărul turei la care s-a ajunsnextsimulează un pas, mișcând toate săgețile și trece la următoarea tură
Atunci când o săgeată lovește o țintă (intră în raza ei), acea țintă incrementează un contor, astfel încât fiecare țintă în parte să știe de câte ori a fost nimerită. Puteți crea clase noi, sau modifica orice ați scris anterior după cum considerați că are cel mai mult sens. Recomandăm crearea unei clase
GameLogicHandlercare să gestioneze turele și săgețile active, pentru a fi mai ușoară și elegantă implementarea. -
Adăugați mai multe tipuri de
Bow, de exempluShortbowșiLongbowcare moștenesc de laBowși îi permit jucătorului să tragă cu alți parametri. Se poate schimba tipul de arc utilizat în joc prin directivaset bowname, undebownameeste numele categoriei de arc.
Static și Operatori
Static
Cu ajutorul keywordului static putem declara variabile care țin de clasă, nu de obiect. Funcționează similar cu o variabilă globală, doar că izolat pentru o clasă.
class Employee {
private:
static uint32_t employeeCount;
uint32_t employeeID;
public:
Employee() {
employeeCount++;
employeeID = employeeCount;
}
uint32_t getEmployeeID() {
return employeeID;
}
};
uint32_t Employee::employeeCount = 0;
int main() {
Employee employee1;
Employee employee2;
Employee employee3;
std::cout << employee1.getEmployeeID() << '\n'; // 1
std::cout << employee2.getEmployeeID() << '\n'; // 2
std::cout << employee3.getEmployeeID() << '\n'; // 3
return 0;
}
Din păcate, membrii statici trebuie inițializați în afara clasei după ce sunt declarați în clasă. Similar, putem declara și metode statice. Dacă adăugăm la clasa de mai devreme:
static void getEmployeeCount() {
return employeeCount;
}
secvența următoare se va comporta astfel:
Employee employee1;
Employee employee2;
Employee employee3;
std::cout << employee1.getEmployeeCount() << '\n'; // 3
std::cout << Employee::getEmployeeCount() << '\n'; // 3
Cele 2 apeluri sunt același lucru. Atât membri statici, cât și metodele staticve pot fi apelate de pe clasă, fără un obiect, dar și de pe orice obiect.
Operatori
Putem supraîncărca majoritatea operatorilor uzuali în C++.
class Vector2 {
private:
float x;
float y;
public:
Vector2(float x, float y) {
this->x = x;
this->y = y;
}
Vector2 operator +(const Vector2 &other) const {
return Vector2(x + other.x, y + other.y);
}
Vector2 &operator =(const Vector2 &other) {
x = other.x;
y = other.y;
return *this;
}
// Prefix
Vector2 operator ++() {
++x;
++y;
return *this;
}
// Postfix
Vector2 operator ++(int) {
Vector2 old(x, y);
++x;
++y;
return old;
}
friend std::istream &operator >> (std::istream &is, Vector2 &vec) {
is >> vec.x >> vec.y;
return is;
}
friend std::ostream &operator << (std::ostream &os, const Vector &vec) {
os << vec.x << ' ' << vec.y;
return os;
}
};
Cel mai intuitiv operator de supraîncărcat este +. constul de dinainte de { stabilește ca obiectul curent nu poate fi modificat. Un exemplu puțin mai neobișnuit este =, la care trebuie avută puțină grijă dacă vrem să funcționeze o instrucțiune de forma a = b = c. Aici, se execută b = c care întoarce o referință la b, după care se continuă cu a = b astfel încât toate devin egale cu c la final.
Operatorii de incrementare și decrementare sunt mai neobișnuiți. Fiind același operator atât la preincrementare cât și la postincrementare, se diferențază prin faptul ca postincrementarea are un parametru de tip int inutil (de asta nici nu îi dăm nume).
Operatorii de citire și afișare sunt iarăși mai ciudați din cauza friend. Ce se întâmplă, de fapt, acolo, este că supraîncărcările operatorilor << și >> nu fac parte din clasă. friend denotă ca o funcție are acces la membrii privați ai clasei (astfel încât să putem citi și afișa). Operatorii întorc o referință la un stream după ce acesta este modificat cu ceea ce citim/afișăm pentru a putea fi înlănțuite. Cu implementarea de mai sus, funcționează corect std::cin >> a >> b unde a și b sunt de tip Vector2.
Exerciții
- Creați clasa
Complexcare modelează un număr complex și supraîncărcați toți operatorii care au sens din punct de vedere matematic și>>,<<, preincrementare, postincrementare.
Fișere
Toate fișierele sunt o înșiruire de bytes, indiferent de extensie. În realitate, extensia nu contează la nimic! Dacă numim un fișier text a.exe și îl deschidem cu un editor de text, va funcționa exact ca un a.txt. La fel, dacă numim executabilul unui joc video main.cpp și îl rulăm din consolă, va porni jocul ca și cum nu ar fi nimic greșit. Diferența între fișiere se face prin format. Fiecare tip de fișier (.pdf, .xlsx, .bmp, etc.) începe cu câțiva bytes (file header) care îl identifică în mod unic astfel încât un program să își poată da seama cum să îl gestioneze.
Fișiere text
Fișierele cu care suntem obișnuiți de la probleme de algoritmică sunt fișiere text. Ele nu au file header specific, și în realitate funcționează ca orice alt fișier, doar că cin interpretează fiecare byte ca un caracter ASCII și ne mai ajută sărind peste spații atunci când citim numere, etc.
Fișiere binare
C Style
O secvență completă de instrucțiuni pentru citirea unui fișier ca binar în C este următoarea:
FILE *fileIn = fopen(fileName, "rb");
fseek(fileIn, 0, SEEK_END);
uint32_t fileLen = ftell(fileIn);
uint8_t *buffer = (uint8_t *) malloc(fileLen);
fseek(fileIn, 0, SEEK_SET);
fread(buffer, sizeof(uint8_t), fileLen, fileIn);
fclose(fileIn);
Pentru scriere:
FILE *fileOut = fopen(fileName, "wb");
fwrite(buffer, sizeof(uint8_t), fileLen, fileOut);
fclose(fileOut);
FILE *fileIn = fopen(fileName, "rb") deschide fișierul fileName ca binar pentru citire. Toate modurile de deschidere a unui fișier în C se pot găsi în documentație;
fseek(fileIn, 0, SEEK_END) mută indicatorul de citire la finalul fișierului (la 0 bytes începând cu finalul fișierului).
ftell(fileIn) ne spune câți bytes au fost deja parcurși în fișier. Din moment ce indicatorul este la finalul fișierului deja, ne va da lungimea datelor din fișier. Creăm un buffer de asceastă dimensiune pentru a stoca conținutul.
fseek(fileIn, 0, SEEK_SET) mută indicatorul de citire la începutul fișierului (la 0 bytes de la începutul fișierului).
fread(buffer, sizeof(uint8_t), fileLen, fileIn) stochează la adresa buffer următorii sizeof(uint8_t) * fileLen bytes din fișier, începând cu poziția actuală a indicatorului de citire.
Exemplul de citire funcționează analog.
C++ Style
O secvență completă de instrucțiuni pentru citirea unui fișier ca binar este următoarea:
std::ifstream fileIn(fileName, std::ios::ate | std::ios::binary);
if (!file.is_open()) {
throw std::runtime_error("Failed to open file");
}
size_t fileLen = (size_t) fileIn.tellg();
std::vector<char> buffer(fileLen, 0);
fileIn.seekg(0);
fileIn.read(buffer.data(), fileLen);
fileIn.close();
Pentru scriere:
std::ofstream fileOut(fileName, std::ios::trunc | std::ios::out);
fileOut.write(buffer.data(), fileLen * sizeof(uint8_t));
fileOut.close();
std::ifstream fileIn(fileName, std::ios::ate | std::ios::binary) deschide fișierul ca binar și mută indicatorul de citire la finalul fișierului. Al doilea parametru este o mască de biți care ne permite să specificăm cum vrem să fie deschis fișierul. Toate opțiunile pentru această mască se pot găsi în documentație
fileIn.tellg() ne spune câți bytes au fost deja parcurși în fișier. Din moment ce indicatorul este la finalul fișierului deja, ne va da lungimea datelor din fișier. Creăm un buffer de asceastă dimensiune pentru a stoca conținutul.
fileIn.seekg(0) mută indicatorul de citire la începutul fișierului (byte-ul de indice 0). De aici vom începe citirea efectivă.
fileIn.read(buffer.data(), fileLen) citește fileLen bytes și îi stochează la adresa de memorie care începe cu adresa dată ca primul parametru. buffer.data() întoarce pointerul către inceputul datelor efective din vectorul STL numit buffer.
fileOut.write(buffer.data(), fileLen) scrie fileLen bytes începând cu adresa datelor efective cu vectorul STL buffer.
Formatul de Fișier .bmp
bmp este un format de fișier simplu pentru imagini. Nu are compresie, ca png sau jpg, deci poate fi manipulat mult mai ușor. Întreaga specificație a formatului de fișier este disponibilă pe Wikipedia și nu va fi reexplicat aici.
Datele efective din imagine sunt ținute în format RGB, culorile fiind compuse din roșu, verde și albastru. Cele 3 canale de culori pot lua valori între 0 și 255. O observație importantă este că o culoare este o nuanță de gri dacă și numai dacă r = g = b.
Exerciții
- Creați o interfață numită ```FileHandler`` care va avea următoarele metode publice:
uint8_t *readBinaryFile(std::string fileName): întoarce adresa la care stochează datele citite binar din fișierulfileNamevoid writeBinaryFile(std::string fileName, uint8_t *buffer): scrie datele dinbufferca binar în fișierulfileNameImage *readImage(std::string fileName): creează un obiect de tip imagine și întoarce un pointer către acesta. Trebuie creată și clasaImageîn care se află toate datele utile din fișierulfileNamede tipbmp. O puteți lăsa neimplementată momentan.void writeImage(std::string fileName, Image *image): scrie în fișierulfileNametoate datele unei imagini de tipbmp, unde structura fișierului este corectă și dedusă din starea obiectului aflat la adresaimage.
- Completați clasa
Image, adăugând un buffer pentru pixelii din imagine și variabile membru pentru toate datele din specificația formatului de care am putea avea nevoie pentru afișare sau logică. - Extindeți interfața
FileHandlercu clasaCFileHandlerși implementați, adăugând orice metode auxiliare aveți nevoie. - Extindeți interfața
FileHandlercu clasaCPPFileHandlerși adăugați orice metode auxiliare aveți nevoie. - În
main, lucrați doar cuFileHandler. NiciodatăCFileHandlersauCPPFileHandler, mai puțin la declarare. De exemplu, aveți voieFileHandler *fileHandler = new CFileHandler(). Schimbând acest unic rând, programul trebuie să funcționeze cu sintaxa de C sau sintaxa de C++. - Completați clasa
Imagecu metodaImage *createGreyscaleImage()care să creeze o imagine nouă, doar că în alb-negru. Puteți folosi formula de transformare a unei culori în nuanță de gri:gray = 0.3 * r + 0.59 * g + 0.11 * b.
Strctura unui proiect C++
Structura unui proiect C++ este destul de simplă și comprehensivă. O structură bună ajută la înțelegerea funcționării proiectului, la modul în care fișierele, sau clasele, relaționează unele cu altele.
.cpp și .h
C++ prezintă două timpuri de fișiere mari și late, .h și .cpp. Primul dintre acestea este un fișier de tip header, iar al doilea este un fișier de tip sursă. Fișierele .h prezintă prin convenție declarațiile, în timp ce fișierele .cpp păstrează definițiile. O clasă va avea în mod normal un header și un source.
Un exemplu este: Player.h
#ifndef SRC_PLAYER_H__
#define SRC_PLAYER_H__
class Player {
public:
Player();
void HealByAmount(uint_32 amount);
private:
uint32_t m_maxHealth;
uint32_t m_health;
static GameMode *s_GameMode;
};
#endif // SRC_PLAYER_H__
Player.cpp
#include <Player.h>
#include <algorithm>
GameMode Player::s_GameMode = nullptr;
Player::Player() {
m_health = m_maxHealth;
}
void Player::HealByAmount(uint_32 amount) {
m_health += amount;
m_health = std::clamp(m_health, 0, m_maxHealth);
}
File linking
Fișierele sunt mai întâi compilate și apoi linkate. Faptul ca acestea pot interacționa este asigurat de utilizarea #include, urmat de adresa fișierului. Acesta face practic o copie a întregului fișier în locația respectivă, de aceea folosirea lor nu trebuie abuzată.
Pot apărea cazuri în care includem un fișier care este deja inclus într-un fișier inclus. Pentru a evita asta există condiții de incluziune. Directiva #ifndef, urmată de un nume, verifică dacă există deja definirea tipului de date. Dacă aceasta nu există, este creat folosind directiva #define, urmată de un nume si de definire. Condiția se încheie folosind directiva #endif.
În exemplul dat, atunci cand dăm include la Player.h, directiva verifică dacă SRC_PLAYER_H__ există deja. Dacă nu, îl include. Dacă există, nu îl va rescrie. În acest mod se previne declararea dublă.
Crearea claselor în CLion
CLion oferă o interfață facilă pentru crearea de clase, headere sau surse.
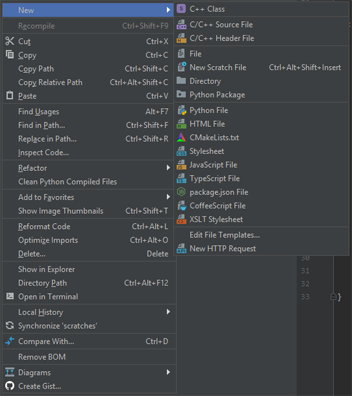
Pentru a crea o clasă poți da click dreapta în ierarhia fișierelor, new, C++ class. Aici poți menționa numele clasei pe care vrei să o creezi.
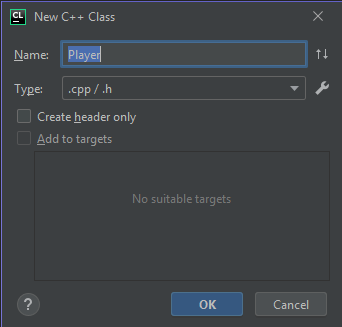
Astfel vor fi create 2 fișiere: un header și un source, ambele avnând numele clasei. CLion le va inițializa default cu directive și cu definiția clasei, iar în fișierul sursă va include fișierul header.
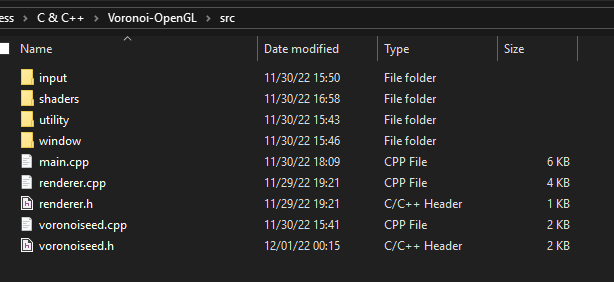
Organizarea fișierelor
Este bine ca fișierele să fie organizate în foldere, în funcție de criterii prestabilite. Toate acestea ar trebui sa se afle într-un folder src, prin convenție în root.
Exerciții
- Restructurați tema începută la Cursul 4 astfel încât fiecare clasă a sa să aibă header și implementare.
STL - partea I
STL este un set de clase care vine cu câteva structuri de date precum vector, map, set, stack, queue si deque. Este bine să le utilizăm, deoarece acestea sunt eficientizate, în majoritatea cazurilor reprezentând cea mai bună soluție.
<vector>
Vectorul este o alternativă foarte comodă la un array clasic, deoarece acesta are implementată alocarea dinamică și alte funcționalități.
-
(constructor)
1. vector(); 2. explicit vector( const Allocator& alloc ); 3. explicit vector( size_type count, const T& value = T(), const Allocator& alloc = Allocator() );- Inițializează un vector gol.
- Inițializează un vector cu elementele specificate.
- Inițializează un vector cu
nelemente cu valoareax.
Exemplu
std::vector<int> v1; std::vector<int> v2 { 1, 2, 3 }; std::vector<int> v3 (5, 0); -
at
constexpr reference at( size_type pos ); constexpr const_reference at( size_type pos ) const;Returnează o referință la elementul de la
pos, dacă este în limita vectorului. Dacă nu, aruncă o excepție.Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; data.at(1) = 9; std::cout << data[1]; // Se afișează: 9 -
front
constexpr reference front(); constexpr const_reference front() const;Returnează o referință la primul element din vector.
Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.front(); // Se afișează: 1 -
back
constexpr reference back(); constexpr const_reference back() const;Returnează o referință la ultimul element din vector.
Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.back(); // Se afișează: 6 -
empty
bool empty() const noexcept;Returnează
falsedacă vectorul are elemente șitruedacă nu are.Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.empty(); // Se afișează: false -
size
size_type size() const noexcept;Returnează numărul de elemente dintr-un vector.
Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.size(); // Se afișează: 6 -
clear
void clear() noexcept;Șterge toate elementele din vector.
Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; data.clear(); std::cout << data.size(); // Se afișează: 0 -
insert
iterator insert( const_iterator pos, const T& value );Inserează
valueînainte de pozițiapos.Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; auto it = data.begin(); data.insert(it, 10); std::cout << data[0]; // Se afișează: 10Pentru mai multe, a se consulta documentația.
-
erase
1. iterator erase( const_iterator pos ); 2. iterator erase( const_iterator first, const_iterator last );- Șterge elemetul de la poziția
pos. - Șterge elementele dintre pozițiile
firstșilast.
Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; auto bg = data.begin(); auto ed = data.end(); data.erase(bg, ed); std::cout << data.size(); // Se afișează: 0 - Șterge elemetul de la poziția
-
push_back
void push_back( const T& value ); void push_back( T&& value );Adaugă
valuela finalul vectorului.Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; data.push_back(7); std::cout << data[6]; // Se afișează: 7 -
pop_back
void pop_back();Elimină ultimul element al vectorului.
Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; data.pop_back(); std::cout << data.size(); // Se afișează: 5 -
resize
void resize( size_type count ); void resize( size_type count, const value_type& value );Schimbă mărimea vectorului la
count. Dacă mărimea inițială este mai mare, se șterg ultimele elemente. Dacă mărimea inițială este mai mică se inserează valori default în pozițiile noi, sauvaluedacă este transmisă.Exemplu
std::vector<int> data = { 1, 2, 4, 5, 5, 6 }; data.resize(10, 0); std::cout << data[8]; // Se afișează: 0
Iteratori
Iteratorii sunt folosiți pentru a arăta către locuri din memorie ale containerelor din STL și prezintă posibilitatea de a itera prin elemente. Un exemplu de iterator este un pointer, dar în STL, aceștia sunt mai complecși de atât. Aceștia reduc complexitatea și timpul de execuție al programelor. Vom vorbi mai în detaliu despre ei cursul viitor.
Funcții din STL
-
begin
Returnează un iterator către primul element al containerului.constexpr iterator begin() noexcept; -
end
Returnează un iterator către ultimul element al containerului.constexpr iterator end() noexcept;
Exemplu
#include <algorithm>
#include <iostream>
#include <vector>
int main() {
std::vector<int> v { 1, 2, 4, 8, 16 };
std::vector<int> e;
// declararea unui iterator
std::vector<int>::iterator it = v.begin();
if (!v.empty()) {
std::cout << *v.begin() << '\n';
}
if (e.begin() == e.end()) {
std::cout << "Vector e is empty";
}
return 0;
}
// Se afișează: 1
// Vector e is empty
Sortarea
Pentru sortarea vectorilor se folosește funcția sort inclusă în <algorithm>.
template< class RandomIt, class Compare >
constexpr void sort( RandomIt first, RandomIt last, Compare comp );
Aceasta parcurge elementele dintre iteratorii first si last și le sortează după regula comp, care este o funcție proprie de sortare, ce returnează un bool.
Exemplu
#include <iostream>
#include <vector>
#include <algorithm>
bool cmp(const int &a, const int &b) {
return a < b;
}
int main() {
std::vector<int> data = { 1, 6, 4, 5, 5, 6 };
std::sort(data.begin(), data.end(), cmp);
for (int x : data) {
std::cout << x << ' ';
}
return 0;
}
// Se afișează: 1 4 5 5 6 6
Lambda expressions
Lambdaurile sunt o modalitate convenabilă de a declara funții local, doar acolo unde sunt necesare.
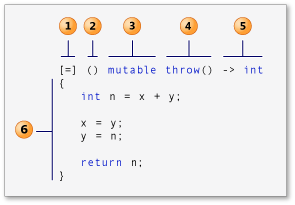
Anatomie
Anatomia unei funții lambda este foarte similară cu cea a unei funcții.
Exemplu
std::sort(x, x + n,
// Lambda expression begins
[](float a, float b) {
return a < b;
}
// End of lambda expression
);
-
capture clause - aici se specifică ce variabile din afara funcții lambda vor fi folosite. Acestea pot fi pasate prin valoare sau prin referință, utilizând
&, urmat de numele variabilei. Dacă dorim toate variabilele să fie incluse prin valoare putem utiliza doar un=, respectiv&, prin referință. Cu toate acestea, nu este o practică bună să trimitem toate variabile exterioare unui lambda.Exemplu
[&a, b] - a este trimis prin referință [&, b] - toate variabilele sunt trimise prin referință, în afară de b care e transmis prin valoare [=, &b] - toate variabilele sunt trimise prin valoare, în afară de b care este transmis prin referință -
parameter list - aici se specifică ce parametri îi vor fi pasați funcției lambda
-
mutable specification
-
exception-specification
-
trailing-return-type - aici se specifică tipul de date returnat
-
lambda body - aici se scrie funcționalitatea
Utilitate
Lamdaurile sunt foarte utile în general, atunci când nu vrem să poluăm codul cu funcții. Un exemplu foarte bun este în cazul sortărilor, când vrem să sortăm același lucru dupa mai multe criterii diferite. Exemplu
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v;
std::vector<int> idx;
// sortează v descrescător
std::sort(v.begin(), v.end(), [](const int &a, const int &b) {
return a > b;
});
// sortează v crescător
std::sort(v.begin(), v.end(), [](const int &a, const int &b) {
return a < b;
});
// sortează indicii lui idx după v[idx]
std::sort(idx.begin(), idx.end(), [=, &v](const int &a, const int &b) {
return v[a] < v[b];
});
return 0;
}
Se observă că în acest fel evităm declararea multor funții cmp pe care le-am folosi poate o singură dată.
Interfețe funcționale
Interfețele funcționale pot categorisi funcțiile. Fiecare interfață funcțională are o singură metodă abstractă, numită metodă funcțională pentru acea interfață funcțională, la care sunt potriviți sau adaptați parametrii expresiei lambda și tipurile de returnare.

Parcurgerea
Iteratorii sunt foarte utili la a parcurge în ordine elementele dintr-un conatiner STL.
template< class InputIt, class UnaryFunction >
constexpr UnaryFunction for_each( InputIt first, InputIt last, UnaryFunction f );
Funcția for_each iterează printre elementele dintre iteratorul first și last, luând ca parametru funcția f, pentru a manipula elementele prin care iterează. Funcția f ia ca parametru referința elementului curent iterat.
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
std::for_each(v.begin() + 5, v.end(), [](int &v) {
v = 2;
});
std::for_each(v.begin(), v.end(), [](int &v) {
std::cout << v << ' ';
});
return 0;
}
// Se afișează: 1 2 3 4 5 2 2 2 2 2
auto
auto se folosește pentru a inițializa variabile. Acesta îi spune compilatorului să stabilească sau să deducă tipul de date din context. Acesta nu este un tip de date separat sau special, ci doar un placeholder.
Este comună folosirea acestuia mai ales în situații când numele tipului de date folosit este complicat, greu de scris, ascuns sub mai multe niveluri de abstractizare. De asemenea, acesta se poate folosi chiar și pentru a salva un lambda. Cu toate acestea, utilizarea sa excesivă poate crea confuzie sau chiar erori, de aceea este necesară o convenție de denumire a variabilelor riguroasă.
Exemplu
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> v = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
auto a = 3; // int
auto it = v.begin(); // iterator
auto lambdaFunc = [](int &v) {
v = 2;
}; // lambda
std::for_each(v.begin() + 5, v.end(), lambdaFunc);
std::for_each(v.begin(), v.end(), [](int &v) {
std::cout << v << ' ';
});
return 0;
}
STL - partea II
Funcții comune tuturor containerelor STL
-
empty
bool empty() const noexcept;Returnează
falsedacă setul are elemente șitruedacă nu are.Exemplu
std::set<int> data = { 1, 4, 5, 6 }; std::cout << data.empty(); // Se afișează: false -
size
size_type size() const noexcept;Returnează numărul de elemente dintr-un set.
Exemplu
std::map<int, char> data {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}}; std::cout << data.size(); // Se afișează: 4
Funcții comune pentru vector, set, map și deque
-
clear
void clear() noexcept;Șterge toate elementele din container.
Exemplu
std::set<int> data = { 1, 4, 5, 6 }; data.clear(); std::cout << data.size(); // Se afișează: 0 -
insert
std::pair<iterator, bool> insert( const value_type& value );Inserează
valueîn container.Exemplu
std::set<int> data = { 1, 4, 5, 6 }; data.insert(10); std::cout << data.size(); // Se afișează: 5Pentru mai multe, a se consulta documentația vector | set | map | deque.
-
erase
1. iterator erase( const_iterator pos ); 2. iterator erase( const_iterator first, const_iterator last );- Șterge elemetul de la poziția
pos. - Șterge elementele dintre pozițiile
firstșilast.
Exemplu
std::set<int> data = { 1, 4, 5, 6 }; auto bg = data.begin(); auto ed = data.end(); data.erase(bg, ed); std::cout << data.size(); // Se afișează: 0 - Șterge elemetul de la poziția
<set>
Setul este un container STL asociativ, care conține sortate obiecte de tipul Key. Acestea sunt sortate cu ajutorul unei funcții de comparare, în funcție de Key. Căutarea, eliminarea și inserarea elementelor se realizează în complexitate logaritmică.
-
count
size_type count( const Key& key ) const;Returnează numărul de elemente cu cheia key. Aceasta este fie 0 fie 1, deoarece seturile nu permit duplicate.
Exemplu
std::set<int> data = { 1, 4, 5, 6, 1 }; std::cout << data.count(1) << ' '; std::cout << data.count(3); // Se afișează: 1 0 -
find
iterator find( const Key& key ); const_iterator find( const Key& key ) const;Găsește un element cu cheia
keyechivalentă cheii din set și returnează un pointer. Dacă nu găsește, este returnat iteratorulend().Exemplu
std::set<int> data = { 1, 4, 5, 6, 1 }; if (data.find(5) != data.end()) { std::cout << "found"; } // Se afișează: found -
contains
bool contains( const Key& key ) const;Verifică dacă există un element cu cheia
keyîn set.Exemplu
std::set<int> data = { 1, 4, 5, 6, 1 }; if (data.contains(5)) { std::cout << "found"; } // Se afișează: found
<map>
Mapul este un container STL asociativ, care conține sortate obiecte pereche care conțin o cheie și o valoare. Acestea sunt sortate cu ajutorul unei funcții de comparare, în funcție de Key. Căutarea, eliminarea și inserarea elementelor se realizează în complexitate logaritmică. Acestea sunt un fel de dicționare, permitând accesul rapid la date.
-
at
T& at( const Key& key ); const T& at( const Key& key ) const;Returnează o referință la elementul din map cu cheia
key. Dacă nu există, aruncă o excepție.Exemplu
std::map<int, char> data = {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}}; std::cout << data.at(1); // Se afișează: a -
operator []
T& operator[]( const Key& key );Returnează o referință la elementul din map cu cheia
key. Dacă nu există, inserează cheia respectivă (Din această cauză nu se recomandă folosirea lui).Exemplu
std::map<int, char> data = {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}}; std::cout << data[1]; // Se afișează: a -
count
size_type count( const Key& key ) const;Returnează numărul de elemente cu cheia key. Aceasta este fie 0 fie 1, deoarece mapurile nu permit duplicate.
Exemplu
std::map<int, char> data = {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}}; std::cout << data.count(1) << ' '; std::cout << data.count(4); // Se afișează: 1 0 -
find
iterator find( const Key& key ); const_iterator find( const Key& key ) const;Găsește un element cu cheia
keyechivalentă cheii din map și returnează un iterator. Dacă nu găsește, este returnat iteratorulend().Exemplu
std::map<int, char> data = {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}}; if (data.find(5) != data.end()) { std::cout << "found"; } // Se afișează: found -
contains
bool contains( const Key& key ) const;Verifică dacă există un element cu cheia
keyîn map.Exemplu
std::map<int, char> data = {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}}; if (data.contains(5)) { std::cout << "found"; } // Se afișează: found
Update prin referință
O modalitate comodă de a actualiza elementele din map este prin referință, deoarece nu trebuie să le mai căutăm de fiecare data în map. Exemplu
std::map<int, char> data = {{1, 'a'}, {3, 'b'}, {5, 'c'}, {7, 'd'}};
char& obj = data.at(1);
obj = 'b';
std::cout << data.at(1);
// Se afișează: b
<stack>
Stackul este un container STL care se oferă funcționalitatea unei stive, după principiul ultimul intrat, primul ieșit.
-
top
const_reference top() const;Returnează valoarea din vârful stivei.
Exemplu
std::stack<int> s; s.push(2); s.push(4); std::cout << s.top(); // Se afișează: 4 -
push
void push( const value_type& value );Adaugă elementul
valueîn stivă.Exemplu
std::stack<int> s; s.push(2); std::cout << s.top(); // Se afișează: 2 -
pop
void pop();Elimină elementul din vârful stivei.
Exemplu
std::stack<int> s; s.push(2); s.push(4); s. pop(); std::cout << s.top(); // Se afișează: 2
<queue>
Queueul este un container STL care se oferă funcționalitatea unei cozi, după principiul primul intrat, primul ieșit.
-
front
reference front(); const_reference front() const;Returnează prima valoare din coadă.
Exemplu
std::queue<int> q; q.push(2); q.push(4); std::cout << q.front(); // Se afișează: 2 -
back
reference back(); const_reference back() const;Returnează ultima valoare din coadă.
Exemplu
std::queue<int> q; q.push(2); q.push(4); std::cout << q.back(); // Se afișează: 4 -
push
void push( const value_type& value );Adaugă elementul
valueîn coadă.Exemplu
std::queue<int> q; q.push(2); std::cout << q.front(); // Se afișează: 2 -
pop
void pop();Elimină primul element al cozii.
Exemplu
std::queue<int> q; q.push(2); q.push(4); q.pop(); std::cout << q.front(); // Se afișează: 2
<deque>
Dequeul este un container STL care permite inserția și eliminarea elementelor la ambele capete ale sale. Din această cauză, dequeul este scalabil, dar nu foarte eficient, acesta fiind evitat în programarea competitivă, folosindu-se alte modalități, cum ar fi 2 stive.
-
at
reference at( size_type pos ); const_reference at( size_type pos ) const;Returnează o referință la elementul din deque aflat la poziția
pos. Dacă nu există, aruncă o excepție.Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.at(1); // Se afișează: 2 -
operator []
reference operator[]( size_type pos ); const_reference operator[]( size_type pos ) const;Returnează o referință la elementul din deque aflat la poziția
pos, fără a verifica dacă există. Exemplustd::deque<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data[1]; // Se afișează: 2 -
front
reference front(); const_reference front() const;Returnează primul element din deque.
Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.front(); // Se afișează: 1 -
back
reference back(); const_reference back() const;Returnează ultimul element din deque.
Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; std::cout << data.back(); // Se afișează: 6 -
push_back
void push_back( const T& value ); void push_back( T&& value );Adaugă
valuela finalul dequeului.Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; data.push_back(7); std::cout << data[6]; // Se afișează: 7 -
pop_back
void pop_back();Elimină ultimul element al dequeului.
Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; data.pop_back(); std::cout << data.size[4]; // Se afișează: 5 -
push_front
void push_front( const T& value ); void push_front( T&& value );Adaugă
valuela începutul dequeului.Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; data.push_front(7); std::cout << data[0]; // Se afișează: 7 -
pop_front
void pop_front();Elimină primul element al dequeului.
Exemplu
std::deque<int> data = { 1, 2, 4, 5, 5, 6 }; data.pop_front(); std::cout << data[0]; // Se afișează: 2
Șiruri de caractere
Șirurile de caractere pot fi manipulate în cpp cu ajutorul librăriilor precum <cstring> și <string>. <cstring> oferă mai multe funții ce pot modifica direct un șir de caractere, în timp ce <string> este în sine o clasă cu interfață.
Caracterele sunt în esență doar niște numere, care sunt apoi interpretate de un standard de cod precum UTF-8 și reprezentate ca și caractere.
<cstring>
Pentru a declara un șir liniar de caractere putem sa folosim un vector normal sau un pointer de tip char, practic echivalentul său. Citirea se realizează normal, într-un vector de caractere. Atunci când afișăm un vector de caractere str, putem apela cout << str;, iar caracterele din vector se vor afișa până când caracterul \0 este atins.
\0 este folosit pentru a semnala că un șir s-a finalizat. Deoarece calculatoarele sunt nevoite să parcurgă liniar seturile de memorie, acest caracter practic îi spune calculatorului să ignore ce a mai rămas în setul de memorie dupa caracterul \0.
Exemplu
char s[55] = "abcdemlc";
str[5] = '\0';
cout << str;
// Se afișează abcde
Funcții
strcpy | strncpy | strcat | strncat | strcmp | strncmp | strchr | strrchr | strstr | strtok | strlen
-
strcpy
char * strcpy (char * destination, const char * source);Îl copiază pe
sourceîndestination.Exemplu
char destination[55]; char source[55] = "bac 2024"; strcpy(destination, source); // destination = "bac 2024" -
strncpy
char * strncpy (char * destination, const char * source, int count);Copiază primele
ncaractere dinsourceîndestination.- Dacă
counteste mai mare decâtsourcese va insera\0până la count. - Dacă
sourceeste mai mare decâtcountnu se va insera\0la final.
Exemplu
char destination[55]; char source[55] = "bac 2024"; int count = 3; strncpy(destination, source, count); // destination = "bac" - Dacă
-
strcat
char * strcat (char * destination, const char * source);Îl concatenează în
destinationpesourceîncepând de la primul\0.Exemplu
char destination[55] = "bac "; char source[55] = "2024"; strcat(destination, source); // destination = "bac 2024" -
strncat
char * strncat (char * destination, const char * source, int count);Concatenează primele
ncaractere dinsourceîndestinationîncepând de la\0.- Dacă
counteste mai mare decâtsourcese va copia până la\0.
Exemplu
char destination[55] = "bac"; char source[55] = " 2024567"; int count = 5; strncat(destination, source, count); // destination = "bac 2024" - Dacă
-
strcmp
int strcmp (char * str1, const char * str2);Compară
str1custr2. Continuă până când gasește un caracter diferit sau dă de\0.- Dacă primul caracter care nu se potrivește are o valoare mai mică în
str1decât înstr2returnează o valoare< 0. - Dacă cele două șiruri sunt egale returnează
0. - Dacă primul caracter care nu se potrivește are o valoare mai mare în
str1decât înstr2returnează o valoare> 0.
Exemplu
char str1[55] = "abbeb ca"; char str2[55] = "bbc"; strcmp(str1, str2); // ('e' - 'c') = 2 - Dacă primul caracter care nu se potrivește are o valoare mai mică în
-
strncmp
int strncmp (char * str1, const char * str2, int count);Compară până la n caractere din
str1cu cele dinstr2. Continuă până când gasește un caracter diferit, ajunge lacountsau dă de\0.- Dacă primul caracter care nu se potrivește are o valoare mai mică în
str1decât înstr2returnează o valoare< 0. - Dacă cele două șiruri sunt egale returnează
0. - Dacă primul caracter care nu se potrivește are o valoare mai mare în
str1decât înstr2returnează o valoare> 0.
Exemplu
char str1[55] = "abbeb ca"; char str2[55] = "bbxx"; int count = 2; strncmp(str1, str2, count); // 0 - Dacă primul caracter care nu se potrivește are o valoare mai mică în
-
strchr
char * strchr (char * str, char c);Returnează un pointer către prima apariție a lui
cînstr.- Dacă
cnu este găsit, returneazăNULL.
Exemplu
char str[55] = "bac scoala 2024"; char c = 'a'; strchr(str, c); // "ac scoala 2024" - Dacă
-
strrchr
char * strrchr (char * str, char c);Returnează un pointer către ultima apariție a lui
cînstr.- Dacă
cnu este găsit, returneazăNULL.
Exemplu
char str[55] = "bac scoala 2024"; char c = 'a'; strrchr(str, c); // "a 2024" - Dacă
-
strstr
char * strstr (char * str1, char * str2);Returnează un pointer către prima apariție a lui
str2înstr1.- Dacă
str2nu este găsit, returneazăNULL. - Dacă dă de
\0se oprește.
Exemplu
char str1[55] = "bac scoala 2024"; char str2[55] = "20"; strstr(str1, str2); // "2024" - Dacă
-
strtok
char * strtok (char * str, char * delim);Caută prima secvență care începe cu un
char ccare nu este dindelimși se termină cu unchar cdindelim.- Dacă
stresteNULL, continuă de unde a rămas din invocarea anterioară. - Dacă nu mai găsește, returnează
NULL.
Exemplu
char str[50] = " Da. Probabil? De_bună_seamă!:)"; char delim[10] = "!?.,-;() "; strtok(str, delim); // "Da" strtok(NULL, delim); // "Probabil" strtok(NULL, delim); // "De_bună_seamă" strtok(NULL, delim); // "NULL" - Dacă
-
strlen
int strlen (const char * str);Returnează lungimea lui
str, adică atunci când întâlnește caracterul\0.
Exempluchar s[55] = "Bac2024"; strlen(s); // 7
<string>
Un obiect de tip string reprezintă o secventă de caractere. Clasa string oferă o interrfață prin care obiectele pot fi manipulate. În acest caz, șirurile sunt alocate dinamic, acest lucru putând să afecteze timpul de execuție.
Exemplu
string str = "amomogas";
cout << str;
// Se afișează amomogas
Funcții
size | length | resize | clear | empty | append | insert | replace | push_back | pop_back | find | rfind | substr
-
size / length
size_t size() const; size_t length() const;Returnează mărimea șirului în bytes (1 char = 1 byte).
Exemplu
std::string str("Test 123"); std::cout << str.size(); // Se afisează: 8 -
resize
void resize (size_t n); void resize (size_t n, char c);Schimbă mărimea stringului să fie egală cu
n. Dacă șirul este mai mare, celelalte caractere sunt eliminate, dacă este mai mic, spațiile libere se umplu cu caracterul\0sau cu parametrulc.Exemplu
std::string str("Test 123"); unsigned size = str.size(); str.resize(size + 2, 'a'); std::cout << str; // Se afisează: Test 123aa -
clear
void clear();Șterge întreg conținutul șirului, lungimea acestuia devenind 0.
Exemplu
std::string str("Test 123"); str.clear(); std::cout << str; // Se afisează: -
empty
bool empty() const;Returnează
truedacă șirul este gol (lungimea e 0) saufalsedacă nu este gol.Exemplu
std::string str("Test 123"); std::cout << str.empty(); // Se afisează: false -
append
string& append (const string& str);Adaugă
strla stringul inițial, mărindui lungimea cu lungimea luistr.Exemplu
std::string str("Test"); std::string str2("123"); str.append(str2); std::cout << str; // Se afișează: Test 123Pentru mai multe, a se consulta documentația.
-
insert
string& insert (size_t pos, const string& str);Inserează stringul
strîn stringul inițial, la poziția specificată.Exemplu
std::string str("Test"); std::string str2(" 123 "); str.insert(3, str2); std::cout << str; // Se afișează: Te 123 stPentru mai multe, a se consulta documentația.
-
replace
string& replace (size_t pos, size_t len, const string& str);Schimbă o porțiune din string care începe la
posși are o lungimelencu noulstr.Exemplu
std::string str("Test UNKNOWN"); std::string str2("123"); str.replace(5, 7, str2); std::cout << str; // Se afișează: Test 124Pentru mai multe, a se consulta documentația.
-
push_back
void push_back (char c);Adaugă un caracter la finalul șirului, mărindu-i lungimea cu 1.
Exemplu
std::string str("Test 123"); str.push_back('4'); std::cout << str; // Se afisează: Test 1234 -
pop_back
void pop_back();Șterge un caracter de la finalul șirului, micșorându-i lungimea cu 1
Exemplu
std::string str("Test 123"); str.pop_back(); std::cout << str; // Se afisează: Test 12 -
find
size_t find (const string& str, size_t pos = 0) const; size_t find (const char* s, size_t pos = 0) const; size_t find (const char* s, size_t pos, size_t n) const; size_t find (char c, size_t pos = 0) const;Caută prima apariție a lui
strîntr-un string și returnează poziția sa de început. Dacăpose specificat, atunci caută după, inclusiv, de la pozițiapos.Exemplu
std::string str("pere mere prune mere"); std::string str2("mere"); std::size_t index = str.find(str2, 11); std::cout << index; // Se afișează: 16Pentru mai multe, a se consulta documentația.
-
rfind
size_t rfind (const string& str, size_t pos = npos) const; size_t rfind (const char* s, size_t pos = npos) const; size_t rfind (const char* s, size_t pos, size_t n) const; size_t rfind (char c, size_t pos = npos) const;Caută ultima apariție a lui
strîntr-un string și returnează poziția sa de început. Dacăpose specificat, atunci caută înainte, inclusiv, de la pozițiapos.Exemplu
std::string str("pere mere prune mere"); std::string str2("mere"); std::size_t index = str.find(str2, 11); std::cout << index; // Se afișează: 5Pentru mai multe, a se consulta documentația.
-
substr
string substr (size_t pos = 0, size_t len = npos) const;Returnează un alt șir construit pe baza celui inițial inițializat ca o copie a unui subșir al șirului inițial care începe de la poziția
possi are lungimealen. Dacăleneste lăsat liber, se va considera finalul șirului inițial.Exemplu
std::string str("Cram School Pass 2024!"); std::string newStr = str.substr(0, 11); std::cout << newStr; // Se afisează: Cram School
Design patterns
Un design pattern, sau un model de proiectare, este o soluție generală, repetabilă pentru provocările din proiectarea software. Acesta este un șablon, un model pentru rezolvarea unei probleme, care poate fi adaptat în cazuri specifice.
Utilitate
Modelele de proiectare pot accelera procesul de dezvoltare prin furnizarea de paradigme de dezvoltare și testare. Pentru a crea un model de proiectare este necesar să luăm în calcul problemele ce pot să apară pe parcursul dezvoltării proiectului, în implementare. Reutilizarea unor modele de proiectare standradizate ajută la prevenirea problemelor, chiar și la depistarea lor și îmbunătățesc lizibilitatea codului, pentru a putea fi înțeles mai ușor de alți oameni.
Modelele de design pot fi dezvoltate sau ajustate de fiecare echipă în parte, pe parcurs, reprezentând un limbaj universal în interiorul proiectului.
Factory
Creează o instanță a mai multor familii de clase
Scop și utilitate
Furnizează o interfață pentru crearea familiilor de obiecte înrudite sau dependente, fără a specifica clasele lor concrete. Acest lucru este util atunci când trebuie să instanțiem mai multe obiecte, dar cu proprietăți diferite. Un exemplu ar fi modelele de mașini. Toate sunt mașini, dar au proprietăți diferite, iar fiecare producător poate decide care să fie.
Builder
Separă construcția obiectului în sine de reprezentarea acestuia
Scop și utilitate
Separă construcția unui obiect complex de reprezentarea acestuia, astfel încât același proces de construcție să poată crea reprezentări diferite. Acest lucru este util atunci când pornind de la același agregat și avem mai multe posibilități în care acesta se poate transforma. Un exemplu este un fișier pe care dorim să îl salvăm și avem posibilitatea să îl salvăm ca raw, pdf sau docx.
File newFile;
switch (newFile.type) {
case LIST:
SaveTool::saveAsXCEL(newFile);
break;
case PARAGRAPH:
SaveTool::saveAsDOCX(newFile);
break;
}
Object Pool
Evită achiziționarea și eliberarea costisitoare de resurse prin reciclarea obiectelor care nu mai sunt utilizate
Scop și utilitate
Gruparea de obiecte poate oferi o creștere semnificativă a performanței. Acest model reciclează obiecte pe care programul nu le mai folosește. Acest lucru este util atunci când gestionăm multe obiecte de același tip și nu dorim să pierdem din eficiența programului instanțiând obiecte noi și stergându-le pee cele vechi, ci mai degrabă le reutilizăm pe cele care nu mai sunt de trebuință.
Prototype
O instanță complet inițializată de copiat sau clonat
Scop și utilitate
Specifică tipurile de obiecte pentru creat folosind o instanță prototip și creează obiecte noi prin copierea acestui prototip.
Singleton
O clasă din care poate exista doar o singură instanță
Scop și utilitate
Se asigură că o clasă are o singură instanță și oferă un punct global de acces la ea. Acest lucru este util atunci când dorim să avem o singură instanță a unei clase, precum ar fi un manager.
Exemplu
Un exemplu de singleton poate fi o clasă care administrează timpul global dintr-un joc. Nu avem nevoie de mai multe obiecte, dar pentru a separa logica, este bine să folosim o clasă, un singleton în acest caz.
class Time
{
public:
static Time& GetInstance() {
static Time instance;
return instance;
}
private:
Time() {};
Time(Time const&) = delete;
void operator= (Time const&) = delete;
};
Singletonul nu are un constructor utilizabil. Pentru a accesa interfața clasei, trebuie mai întâi să facem rost de instanța singletonului apelând GetInstance(), care returnează o instanță statică. Abia după aceea, prin intermediul instanței, putem avea acces la interfața clasei.
Decorator / Wrapper
Adăugă responsabilități obiectelor în mod dinamic
Scop și utilitate
Decoratorii oferă o alternativă flexibilă la subclasare pentru extinderea funcționalității. Aceștia funcționează precum adăugarea de decorațiuni unui brad: bradul rămâne același, dar funcționalitatea se schimbă ușor. Un alt exemplu pot fi atașamentele pe armele din jocurile video.
Exemplu
Un exemplu de singleton poate fi o clasă care administrează timpul global dintr-un joc. Nu avem nevoie de mai multe obiecte, dar pentru a separa logica, este bine să folosim o clasă, un singleton în acest caz.
#include <iostream>
class Component {
public:
virtual ~Component() {}
virtual std::string Operation() const = 0;
};
class ConcreteComponent : public Component {
public:
std::string Operation() const override {
return "ConcreteComponent";
}
};
class Decorator : public Component {
public:
Decorator(Component* component) : component_(component) { }
std::string Operation() const override {
return this->component_->Operation();
}
protected:
Component* component_;
};
class ConcreteDecoratorA : public Decorator {
public:
ConcreteDecoratorA(Component* component) : Decorator(component) { }
std::string Operation() const override {
return "ConcreteDecoratorA(" + Decorator::Operation() + ")";
}
};
class ConcreteDecoratorB : public Decorator {
public:
ConcreteDecoratorB(Component* component) : Decorator(component) { }
std::string Operation() const override {
return "ConcreteDecoratorB(" + Decorator::Operation() + ")";
}
};
void Print(Component* component) {
std::cout << component->Operation() << '\n';
}
int main() {
Component* starting = new ConcreteComponent;
Print(starting);
Component* decorator1 = new ConcreteDecoratorA(starting);
Component* decorator2 = new ConcreteDecoratorB(decorator1);
Print(decorator2);
delete starting;
delete decorator1;
delete decorator2;
return 0;
}
Programul va afișa prima dată doar ConcreteComponent, iar a 2-a oară va afișa ConcreteDecoratorB(ConcreteDecoratorA(ConcreteComponent)).
Iterator
Accesează secvențial elementele unei colecții
Scop și utilitate
Iteratorii permit accesarea elementelor unui agregat, fără a expune reprezentarea de bază. Acest lucru este util atunci când dorim să abstractizăm parcurgerea unui set de date și să nu mai interacționăm neapărat cu datele.
Exemplu
Iteratorii sunt folosiți pentru a arăta către locuri din memorie ale containerelor din STL și prezintă posibilitatea de a itera prin elemente. Un exemplu de iterator este un pointer, dar în STL, aceștia sunt mai complecși de atât. Aceștia reduc complexitatea și timpul de execuție al programelor.
Iteratorii lucrează cu pointeri pentru a putea funcționa. O clasă de iteratori ar trebui să aibă ca membri un pointer și un index. Este importnat ca operatorii iteratorilor sa fie rescriși pentru a asigura funcționalitatea dorită. Spre exemplu, operatorul * ar putea să returneze, prin referință, valoarea la care arată iteratorul, operatorul -> ar putea să returneze pointerul, operatorul ++ ar putea să avanseze iteratorul, iar -- să îl retrogradeze. Aceste efecte se pot realiza usor, manipulând pointerul și indexul iteratorului.
class iterator {
private:
T *mPtr;
int mIndex;
private:
// default constructor
iterator() {
mPtr = nullptr;
}
// constructs based on a vector
iterator(const vector<T> &vect) {
*this = vect.begin();
}
// constructs based on a vector and a position
iterator(const vector<T> &vect, T *ptr) {
mPtr = ptr;
mIndex = ptr - vect.vect;
}
public:
// returnează referință la valoarea de la pointerul respectiv
int &operator*() {
return *mPtr;
}
// returnează pointerul
int *operator->() {
return mPtr;
}
Task
- Implementați realocarea de memorie pentru un vector
- Implementați un iterator pentru vectorul vostru
Templateuri
Templateurile permit crearea funcțiilor generice, definite ca un plan sau ca o formulă, ce sunt dezvoltate pentru a funcționa cu mai multe tipuri de date diferite. Acestea se bazează pe ideea transmiterii tipului de date ca parametru, împreună cu valoarea în sine a obiectului, astfel putând scrie același cod pentru mai multe cazuri. Un exemplu este cazul unei sortări. Putem avea mai multe tipuri de obiecte pe care vrem să le sortăm, dar să le putem sorta după un parametru comun.
Exemplu
std::sort(v.begin(), v.end(), []<typename T>(const T &a, const T &b) {
return a.ID > b.ID;
});
Fișiere .hhp
Formatul .hpp este o combinație dintre fișierele de tipul .h și cele de tipul .cpp, iar acesta este specific limbajului c++. Așa cum sugerează și numele, acesta conține atât headere cât și implementarea lor. Clasele care utilizează templateuri trebuiesc definite și implementate în fișiere .hpp, deoarece, în cazul contrat, programul nu ar compila din cauza priorității pe care o au diferite părți din cod la compilare.
Utilizare
Pentru a specifica că o clasă sau o funcție este template, trebuie decorată cu template <>, iar între <> vor fi specificate tipurile de variabile pasate mai departe, către compilator, ulterior către clasa sau funcția compilată. Folosind typename T, declarăm un tip de date de tipul T, acesta putând fi o clasă proprie, un int, un string, orice. Un template acceptă orice număr de parametrii, iar aceștia se trimit când apelăm funcția sau creăm obiectul. De asemenea, aceștia pot fi deduși și de compilator în unele cazuri. Ca o mențiune, putem scrie fie typename, fie class, dar din punctul meu de vedere, typename este mult mai general și deci mai potrivit.
Exemplu
#include <iostream>
#include <vector>
template <typename T>
T Sum(T a, T b) {
return a + b;
}
int main() {
std::cout << Sum<int>(4, 5) << '\n';
std::cout << Sum(4, 5);
std::vector <float> v;
return 0;
}
Cum funcționează
Templateurile îi spun compilatorului ce cod să creeze la compilare pe baza apelurilor. Un template este practic un blueprint, o instrucțiune pentru compilator.
Exemplu
#include <iostream>
template <typename T>
T Sum(T a, T b) {
return a + b;
}
int main() {
std::cout << Sum(4, 5) << '\n';
std::cout << Sum(4.5f, 5.6f);
return 0;
}
În exemplul de mai sus, compilatorul își face 2 funcții, pentru fiecare apel cu un tip de date diferit. Acesta este echivalent cu exemplul de jos, doar că în cel de jos avem, într-o măsură evitabilă prin folosirea templateurilor, cod duplicat.
Exemplu
#include <iostream>
int Sum(int a, int b) {
return a + b;
}
float Sum(float a, float b) {
return a + b;
}
int main() {
std::cout << Sum(4, 5) << '\n';
std::cout << Sum(4.5f, 5.6f);
return 0;
}
Templateurile merg la fel de bine și pe clase. De asemenea,prin templateuri putem să trimitem și valori. Un caz ar putea fi dimensiunile unui array, deoarece acestea trebuie specificate la run time. Acestor variabile le pot fi atribuite și valori default.
Exemplu
#include <iostream>
template <typename T, int N = 10>
class vector {
public:
T v[N];
T& operator [] (int idx) {
return v[idx];
}
};
int main() {
vector <char, 5> v;
v[1] = 'a';
std::cout << v[1];
vector <int> u;
return 0;
}
Când se folosesc
Templateurile sunt foarte puternice, deoarece acestea comunică direct cu compilatorul și îi spun practic ce să scrie. Acestea sunt scalabile, un exemplu pentru asta fiind o funcție de logging, care poate afișa inturi, stringuri, floaturi, etc, doar folosind un typename. Cu toate acestea, templateurile nu treebuiesc abuzate. Codul poate deveni mult mai greu de urmărit, iar erorile pot fi mult mai greu de depistat. Unele companii chiar le interzic.
Task
-
Implementați o funcție de sortare care să poate sorta mai multe tipuri de date pe baza unei variabile
m_ID. Definiți și cel puțin 2 tipuri de date cu un membrum_ID, care să aibă un getter și un setter pentru această variabilă privată. -
Faceți un singleton
Logger, care să conțină o singură metodăLog, care poate afișa orice tip standard de date, și o variabilă cu getter și setter, care să numere de câte ori ați afișat ceva. -
Adăugați templateuri la vectorul vostru.
-
Adăugați templateuri si la iterator.
Multithreading
Multithreading este un proces care permite rularea mai multor părți de cod simultan, pentru a maximiza utilizarea procesorului. Fiecare parte separată din această execuție se numește thread și este
Utilizare
Pentru a lansa un thread se apelează std::thread obj(f, params). De asemenea, funția poate fi declarată și ca un lambda, apoi apelată.
Exemplu
#include <iostream>
#include <thread>
void f(int i) {
std::cout << i << '\n';
}
int main() {
std::thread thread_obj(f, 1);
return 0;
}
Pentru a aștepta ca threadurile să se termine, se apelează .join(). Asta garantează că codul așteaptă terminarea threadului, apoi trece mai departe.
Exemplu
#include <iostream>
#include <thread>
void f(int i) {
std::cout << i << '\n';
}
int main() {
std::thread thread_obj(f, 1);
thread_obj.join();
std::cout << 2;
return 0;
}
Acesta este un exemplu care adună elementele unui vector de 100 de elemente, 10 câte 10, în același timp. Teoretic eficiența acestui program ar trebui să fie O(sqrt(n)), dar din cauza latenței inițializerii unui thread, acesta nu este chiar cazul. Exemplu
#include <iostream>
#include <thread>
#include <vector>
int v[100];
int u[100];
void Init() {
for (int i = 0; i < 100; i++) {
v[i] = i;
u[i] = i;
}
}
void Sum(int idx) {
std::cout << v[idx] + u[idx] << '\n';
}
int main() {
Init();
std::vector <std::thread*> vec;
for (int i = 0; i < 100; i++) {
auto t = new std::thread(Sum, i);
vec.push_back(t);
}
for (auto x : vec) {
x->join();
}
return 0;
}
Task
Scrieți o funcție care ia ca parametru un id și afișează "Eu sunt threadul cu IDul id". Porniți câte un thread cu această funcție având ca id toate valorile de la 0 la 99. Observați outputul.
Thread Pool
Este costisitor să creăm threaduri noi de fiecare data. Din această cauză, se obișnuiește utilizarea thread poolurilor. Acestea sunt practic niște object pooluri, prezentate în cursul de Design Patterns.
Race Condition
Race condition apare atunci când mai multe threaduri manipulează aceeași informație. În exemplul de mai jos este exemplificat acest lucru. Problema la threaduri este că nu putem știi ordinea de execuție, așa că pot apărea probleme când manipulăm aceeași informație.
Exemplu
#include <iostream>
#include <thread>
int i;
void f() {
i++;
std::cout << i << '\n';
}
int main() {
std::thread thread_obj1(f);
std::thread thread_obj2(f);
thread_obj1.join();
thread_obj2.join();
return 0;
}
Mutex
O soluție este folosirea unui mutex. Acesta poate permite sau bloca execuția programului după următoarea regulă: doar după ce s-a apelat lock() se poate apela unlock(), iar lock() nu se poate apela dacă nu s-a dat unlock() la lock-ul anterior. Acest lucru asigură executarea în ordinea dorită a threadurilor.
Exemplu
#include <iostream>
#include <thread>
#include <mutex>
std::mutex m;
int i;
void f() {
m.lock();
i++;
std::cout << i << '\n';
m.unlock();
}
int main() {
std::thread thread_obj1(f1);
std::thread thread_obj2(f2);
thread_obj1.join();
thread_obj2.join();
return 0;
}
În general e bine ca un mutex să dea lock la o singură informație în parte, pentru a nu exista conflicte.
Deadlock
Deadlock este o problemă care se poate întâlni atunci când lucrăm cu threaduri si mutexuri. Ceea ce se întâmplă este că execuția se poate bloca. Este mult mai ușor de ilustrat cum se întamplă printr-un exemplu.
Exemplu
#include <iostream>
#include <thread>
#include <mutex>
std::mutex A;
std::mutex B;
void f1() {
A.lock(); // op 1
B.lock(); // op 3 (begins waiting)
A.unlock();
B.unlock();
}
void f2() {
B.lock(); // op 2
A.lock(); // op 4 (begins waiting)
A.unlock();
B.unlock();
}
int main() {
std::thread thread_obj1(f1);
std::thread thread_obj2(f2);
thread_obj1.join();
thread_obj2.join();
return 0;
}
Similar, se aplică și la alocare, deoarece crearea și ștergerea de memorie respectă regula parantezării corecte.
Exemplu
new a;
new b;
delete b;
new c;
new d;
delete d;
delete c;
delete a;
O altă situație mai concretă poate fi reprezentată de întâlnirea dintre un gang care are un prizonier și polițiștii care au valiza cu bani pentru răscumpărare. Atunci când polițiștii le spun bandiților să le dea mai întâi prizonierul, ei cer valiza și vice versa.
Semaphore
Semaphore este un fel de mutex cu flaguri. Practic ne putem imagina o cameră cu mai multe uși în care pot intra maxim 5 oameni în orice moment din timp. Cum obținem asta? Ținând un contor. Dacă intră unul creștem contorul, iar dacă iese îl scădem. Dacă contorul este egal cu 5, nu mai lăsăm lume să intre.
Un exemplu mai concret este înfățișat în minecraft de mob cap. Dacă avem 5 spawnere și o limită de spawnat a mobilor de 32, fiecare spawner va încerca să spawneze un mob, dacă sunt mai puțini de 32. De asemenea, mobii pot muri, astfel eliberând mob capul.
Exemplu
#include <iostream>
#include <thread>
#include <semaphore>
#include <mutex>
std::counting_semaphore<32> prepareSignal(0);
std::mutex mobLock;
int mobCount = 0;
void HandleDeath(int ticksToGo) {
if (ticksToGo-- <= 0) {
return;
}
prepareSignal.release();
mobLock.lock();
mobCount--;
mobLock.unlock();
}
void HandleSpawning(int ticksToGo) {
if (ticksToGo-- <= 0) {
return;
}
prepareSignal.acquire();
mobLock.lock();
mobCount++;
mobLock.unlock();
}
int main() {
std::thread spawnThread(HandleSpawning, 10000);
std::thread deathThread(HandleSpawning, 10000);
return 0;
}
Acquire și Release se mai pot întâlni și sub denumirea de Up și Down.
Task
Acum este rândul vostru să folosiți noțiunile învățate.
- Creați o clasă GameHandler, singleton, care să aibă un game loop.
- Simulați un autobuz în care se pot urca pasageri. Acesta are o variabilă constantă cu numărul maxim de pasageri, egală cu 20, o variabilă cu numărul pasagerilor, o funcție prin care îl poate crește și alta prin care îl poate descrește.
- Scrieți o clasă statică care să genereze inturi aleatorii.
- Simulați cum la fiecare stație se urcă și coboară un număr aleator de oameni în autobuz.
- Simulați urcarea și coborârea pasaherilor folosind threaduri.